Nutrient.io
A developer-first PDF-to-markdown API that handles straightforward OCR and hierarchy well, but loses fidelity on complex tables, charts, and handwritten visual content.
Good text extraction, weak document fidelity
Nutrient.io worked as a hosted API for turning mixed PDFs into markdown, and it did a respectable job preserving headings, section structure, and readable OCR on straightforward pages. But in this use case, the hard parts were exactly where it slipped: complex financial tables lost header relationships, charts were flattened into text or garbled OCR, handwritten signatures were omitted, and one scanned title page came back in the wrong reading order. It looks usable for developer workflows that mostly need text and basic structure, but not for high-trust markdown conversion of complex PDFs without cleanup.
In-Depth Review
Our detailed analysis of Nutrient.io — features, performance, and real-world testing.
Feature-by-Feature Breakdown
Programmatic PDF-to-markdown extractionWorks via API, but the tested workflow depended on code rather than the web UI.▾
Feature tested: Programmatic PDF-to-markdown extraction
Result: Passed
Verdict: Works via API, but the tested workflow depended on code rather than the web UI.
Expected behavior: Nutrient accepts multi-page PDFs and returns markdown output files programmatically. In testing, it processed an 84-page hybrid earnings report, an 18-page table-heavy financial report, and a scanned research paper. The researcher noted that the web UI timed out, so the successful path was the API-key workflow shown in Nutrient's documentation.
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): 84-page hybrid earnings report with native text, charts, tables, and a scanned signatures page. — llamaparse-hybrid-earnings-pdf-1.pdf
Observed output: Output artifact (Text/code file): Nutrient returned a markdown file for the hybrid earnings report. The report notes that the web UI timed out, so this result was obtained through the API workfl — nutrient-io-nutrient-hybrid-earningspdf-output-2.md
Input artifact: Input artifact (PDF document): 84-page hybrid earnings report with native text, charts, tables, and a scanned signatures page. — llamaparse-hybrid-earnings-pdf-1.pdf
Output artifact: Output artifact (Text/code file): Nutrient returned a markdown file for the hybrid earnings report. The report notes that the web UI timed out, so this result was obtained through the API workfl — nutrient-io-nutrient-hybrid-earningspdf-output-2.md
What changed: PDF document transformed into Text/code file
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): 18-page table-heavy financial report. — llamaparse-sumitomo-financial-pdf-1.pdf
Observed output: Output artifact (Text/code file): Nutrient returned parsed markdown for the table-heavy financial report, which the researcher could copy or download. — nutrient-io-nutrient-financialpdf-output-1.md
Input artifact: Input artifact (PDF document): 18-page table-heavy financial report. — llamaparse-sumitomo-financial-pdf-1.pdf
Output artifact: Output artifact (Text/code file): Nutrient returned parsed markdown for the table-heavy financial report, which the researcher could copy or download. — nutrient-io-nutrient-financialpdf-output-1.md
What changed: PDF document transformed into Text/code file
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): Scanned research paper used to test OCR and layout handling. — llamaparse-scanned-research-pdf-1.pdf
Observed output: Output artifact (Text/code file): Nutrient returned parsed markdown for the scanned research report, again through the API-based workflow. — nutrient-io-nutrient-scannedpdf-output-1.md
Input artifact: Input artifact (PDF document): Scanned research paper used to test OCR and layout handling. — llamaparse-scanned-research-pdf-1.pdf
Output artifact: Output artifact (Text/code file): Nutrient returned parsed markdown for the scanned research report, again through the API-based workflow. — nutrient-io-nutrient-scannedpdf-output-1.md
What changed: PDF document transformed into Text/code file
Why it matters / Conclusion: If you are comfortable calling an API, Nutrient can return markdown for mixed PDFs. If you need a dependable browser flow, this research did not show one: the UI timed out and the tested path was code-first.
Nutrient accepts multi-page PDFs and returns markdown output files programmatically. In testing, it processed an 84-page hybrid earnings report, an 18-page table-heavy financial report, and a scanned research paper. The researcher noted that the web UI timed out, so the successful path was the API-key workflow shown in Nutrient's documentation.
Reading order, hierarchy, and OCR text recoveryGood on straightforward pages, but not fully reliable on complex scanned layouts.▾
Feature tested: Reading order, hierarchy, and OCR text recovery
Result: Partial
Verdict: Good on straightforward pages, but not fully reliable on complex scanned layouts.
Expected behavior: Nutrient was strongest when the task was recovering readable text with section structure intact. It preserved heading-to-body relationships on a native-digital annual-report page, recovered dense prose and numeric details from a financial-report page, and handled a scanned two-column research section cleanly. The main weakness was page-level ordering on a more complex scanned first page, where abstract material appeared before the title block.
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Target 2015 Annual Report page titled 'A Growth Story Again' with heading, paragraph text, and bullets. — landing-ai-target-annual-report-growth-story-page.png
Observed output: Output artifact (Image): On the annual-report page titled 'A Growth Story Again,' Nutrient preserved the page heading, introductory paragraph, and bullet hierarchy in readable order, so — nutrient-io-target-annual-report-parsed-document-hierarchy.png
Input artifact: Input artifact (Image): Target 2015 Annual Report page titled 'A Growth Story Again' with heading, paragraph text, and bullets. — landing-ai-target-annual-report-growth-story-page.png
Output artifact: Output artifact (Image): On the annual-report page titled 'A Growth Story Again,' Nutrient preserved the page heading, introductory paragraph, and bullet hierarchy in readable order, so — nutrient-io-target-annual-report-parsed-document-hierarchy.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Financial-report prose page covering assets, liabilities, net assets, and cash flow. — nutrient-io-financial-summary-condition-page-9.png
Observed output: Output artifact (Image): On the financial-report page about assets, liabilities, net assets, and cash flow, Nutrient recovered the numbered sections and key JPY amounts as readable text — nutrient-io-financial-summary-ocr-hierarchy-page-8.png
Input artifact: Input artifact (Image): Financial-report prose page covering assets, liabilities, net assets, and cash flow. — nutrient-io-financial-summary-condition-page-9.png
Output artifact: Output artifact (Image): On the financial-report page about assets, liabilities, net assets, and cash flow, Nutrient recovered the numbered sections and key JPY amounts as readable text — nutrient-io-financial-summary-ocr-hierarchy-page-8.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Scanned two-column page headed 'STUDY AREA'. — landing-ai-scanned-two-column-text-study-area.png
Observed output: Output artifact (Image): On the scanned two-column 'STUDY AREA' page, Nutrient kept the section heading attached to its content and converted the visible column text into coherent parag — nutrient-io-study-area-parsed-section-hierarchy.png
Input artifact: Input artifact (Image): Scanned two-column page headed 'STUDY AREA'. — landing-ai-scanned-two-column-text-study-area.png
Output artifact: Output artifact (Image): On the scanned two-column 'STUDY AREA' page, Nutrient kept the section heading attached to its content and converted the visible column text into coherent parag — nutrient-io-study-area-parsed-section-hierarchy.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Scanned research-note first page with title, authors, abstract start, and margin notes. — nutrient-io-usda-research-note-title-page.png
Observed output: Output artifact (Image): On the scanned research-note first page, Nutrient placed the ABSTRACT and keywords before the title and author block. That makes the text readable, but it is a — nutrient-io-ocr-first-page-abstract-text.png
Input artifact: Input artifact (Image): Scanned research-note first page with title, authors, abstract start, and margin notes. — nutrient-io-usda-research-note-title-page.png
Output artifact: Output artifact (Image): On the scanned research-note first page, Nutrient placed the ABSTRACT and keywords before the title and author block. That makes the text readable, but it is a — nutrient-io-ocr-first-page-abstract-text.png
What changed: Image transformed into Image
Why it matters / Conclusion: Nutrient can produce clean, usable text from both digital and scanned pages when the layout is straightforward. But the title-page ordering miss means you should still spot-check complex scanned layouts before trusting downstream ingestion.
Nutrient was strongest when the task was recovering readable text with section structure intact. It preserved heading-to-body relationships on a native-digital annual-report page, recovered dense prose and numeric details from a financial-report page, and handled a scanned two-column research section cleanly. The main weakness was page-level ordering on a more complex scanned first page, where abstract material appeared before the title block.

Target 2015 Annual Report page titled 'A Growth Story Again' with heading, paragraph text, and bullets.

On the annual-report page titled 'A Growth Story Again,' Nutrient preserved the page heading, introductory paragraph, and bullet hierarchy in readable order, so the section stayed structurally coherent in the extracted output.

Financial-report prose page covering assets, liabilities, net assets, and cash flow.

On the financial-report page about assets, liabilities, net assets, and cash flow, Nutrient recovered the numbered sections and key JPY amounts as readable text blocks, showing that it can preserve dense report prose and section boundaries.

Scanned two-column page headed 'STUDY AREA'.

On the scanned two-column 'STUDY AREA' page, Nutrient kept the section heading attached to its content and converted the visible column text into coherent paragraphs instead of interleaving both columns.

Scanned research-note first page with title, authors, abstract start, and margin notes.

On the scanned research-note first page, Nutrient placed the ABSTRACT and keywords before the title and author block. That makes the text readable, but it is a real reading-order error for a page that mixes title matter, abstract, and body content.
Table extractionMixed to weak: simpler tables survive, but complex financial and scanned tables lose important structure.▾
Feature tested: Table extraction
Result: Partial
Verdict: Mixed to weak: simpler tables survive, but complex financial and scanned tables lose important structure.
Expected behavior: Nutrient can preserve the rough shape of simpler tables, including one scanned table with grouped columns, but it struggled as complexity increased. Across the hybrid earnings report, the table-heavy financial report, and the scanned research paper, the recurring failure mode was loss of row/column alignment and multi-level header relationships. The result was markdown that still contained many values, but often not in a form a human or pipeline could trust without cleanup.
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Scanned table showing original and post-harvest diameters across four treatments. — mistral-ai-scanned-treatment-diameter-table.png
Observed output: Output artifact (Image): For the scanned treatment table, Nutrient preserved the basic grouped columns and row labels well enough for the table to remain mostly readable. It still intro — nutrient-io-parsed-table-stand-structure-before-after-cutting.png
Input artifact: Input artifact (Image): Scanned table showing original and post-harvest diameters across four treatments. — mistral-ai-scanned-treatment-diameter-table.png
Output artifact: Output artifact (Image): For the scanned treatment table, Nutrient preserved the basic grouped columns and row labels well enough for the table to remain mostly readable. It still intro — nutrient-io-parsed-table-stand-structure-before-after-cutting.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Target annual-report financial summary table with year columns and multiple financial line items. — landing-ai-target-annual-report-financial-summary-table-2.png
Observed output: Output artifact (Image): On the Target financial summary, Nutrient recovered many row labels and values, but the table was not faithfully reconstructed. Currency markers and columns bec — nutrient-io-target-annual-report-parsed-complex-table.png
Input artifact: Input artifact (Image): Target annual-report financial summary table with year columns and multiple financial line items. — landing-ai-target-annual-report-financial-summary-table-2.png
Output artifact: Output artifact (Image): On the Target financial summary, Nutrient recovered many row labels and values, but the table was not faithfully reconstructed. Currency markers and columns bec — nutrient-io-target-annual-report-parsed-complex-table.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Segment-performance table with multi-level headers and adjustment columns. — nutrient-io-financial-segment-table-cropped.png
Observed output: Output artifact (Image): On the segment table, Nutrient preserved some cell values but lost the source table's multi-level header organization. Parent-child column relationships were no — nutrient-io-segment-financial-table-by-business-unit.png
Input artifact: Input artifact (Image): Segment-performance table with multi-level headers and adjustment columns. — nutrient-io-financial-segment-table-cropped.png
Output artifact: Output artifact (Image): On the segment table, Nutrient preserved some cell values but lost the source table's multi-level header organization. Parent-child column relationships were no — nutrient-io-segment-financial-table-by-business-unit.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
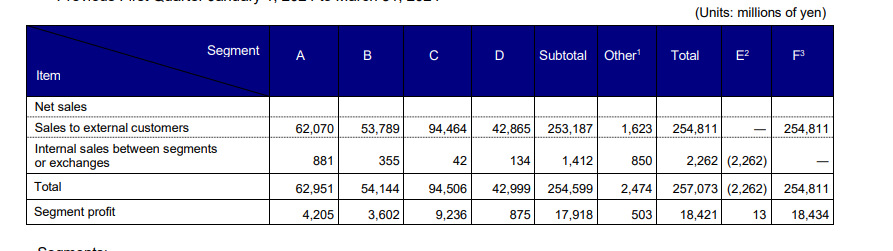
Input used: Input artifact (Image): Quarterly consolidated income-statement table comparing previous and present first-quarter periods. — nutrient-io-quarterly-consolidated-income-statement-table.png
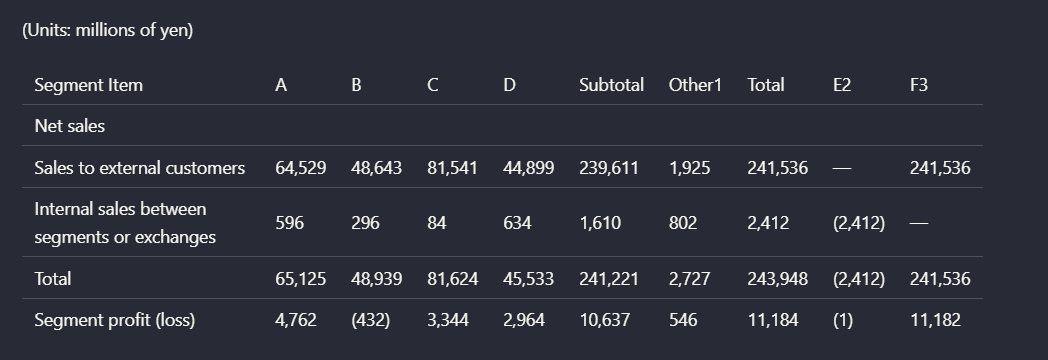
Observed output: Output artifact (Image): On the quarterly income-statement table, Nutrient captured the heading and early line items, but the comparison columns and later content were only partially re — nutrient-io-parsed-quarterly-income-statement-text.png
Input artifact: Input artifact (Image): Quarterly consolidated income-statement table comparing previous and present first-quarter periods. — nutrient-io-quarterly-consolidated-income-statement-table.png
Output artifact: Output artifact (Image): On the quarterly income-statement table, Nutrient captured the heading and early line items, but the comparison columns and later content were only partially re — nutrient-io-parsed-quarterly-income-statement-text.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Scanned table titled 'Trees killed per acre by cutting block, year, cause, and diameter.' — nutrient-io-table-trees-killed-per-acre.png
Observed output: Output artifact (Image): On the complex scanned table, Nutrient lost structural boundaries as table complexity increased. Rows were clipped, some labels were misread, and the relationsh — nutrient-io-parsed-table-trees-killed-per-acre-1.png
Input artifact: Input artifact (Image): Scanned table titled 'Trees killed per acre by cutting block, year, cause, and diameter.' — nutrient-io-table-trees-killed-per-acre.png
Output artifact: Output artifact (Image): On the complex scanned table, Nutrient lost structural boundaries as table complexity increased. Rows were clipped, some labels were misread, and the relationsh — nutrient-io-parsed-table-trees-killed-per-acre-1.png
What changed: Image transformed into Image
Why it matters / Conclusion: Nutrient is acceptable for simpler tables, but it was not dependable on the exact table-heavy cases this use case cares about most: financial summaries, multi-level headers, and dense scanned matrices.
Nutrient can preserve the rough shape of simpler tables, including one scanned table with grouped columns, but it struggled as complexity increased. Across the hybrid earnings report, the table-heavy financial report, and the scanned research paper, the recurring failure mode was loss of row/column alignment and multi-level header relationships. The result was markdown that still contained many values, but often not in a form a human or pipeline could trust without cleanup.

Scanned table showing original and post-harvest diameters across four treatments.

For the scanned treatment table, Nutrient preserved the basic grouped columns and row labels well enough for the table to remain mostly readable. It still introduced OCR mistakes in the first numeric column, turning 7.8, 7.7, 7.4, and 7.5 into 78, 77, 74, and 75.
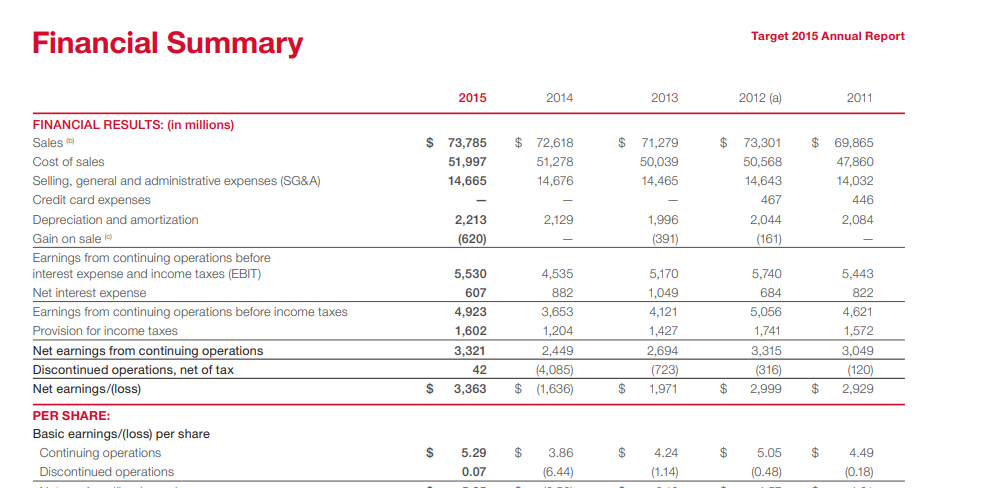
Target annual-report financial summary table with year columns and multiple financial line items.
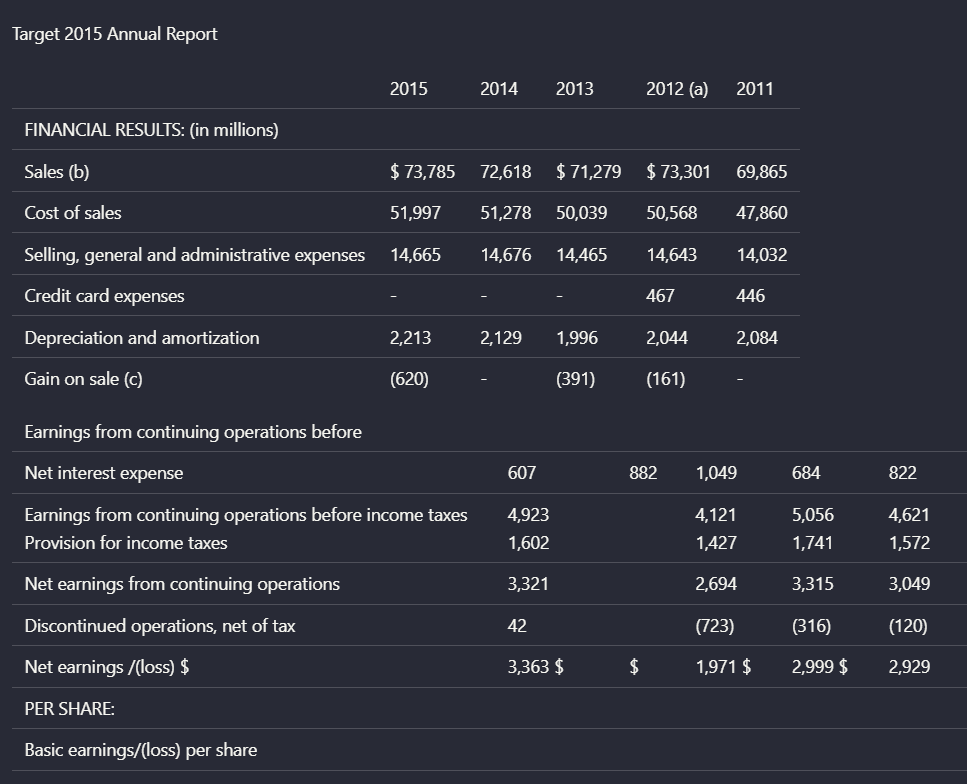
On the Target financial summary, Nutrient recovered many row labels and values, but the table was not faithfully reconstructed. Currency markers and columns became uneven, and the relationship between rows and values weakened enough that the output read more like a flattened grid than a clean financial table.
Segment-performance table with multi-level headers and adjustment columns.
On the segment table, Nutrient preserved some cell values but lost the source table's multi-level header organization. Parent-child column relationships were no longer explicit, which makes the extracted structure harder to trust for analysis.
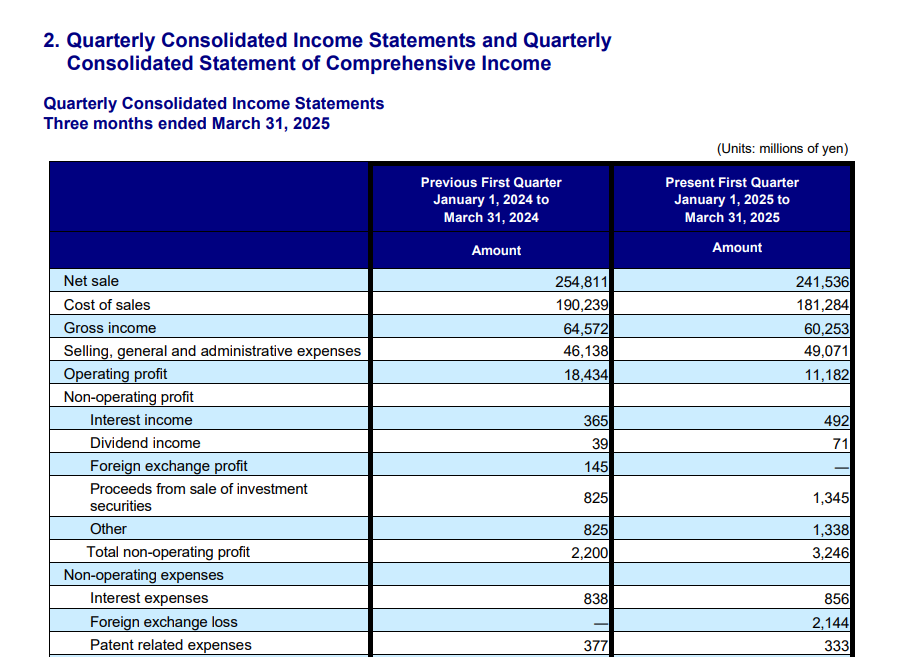
Quarterly consolidated income-statement table comparing previous and present first-quarter periods.

On the quarterly income-statement table, Nutrient captured the heading and early line items, but the comparison columns and later content were only partially represented. The result is a truncated, simplified version of the source table rather than a faithful markdown reconstruction.
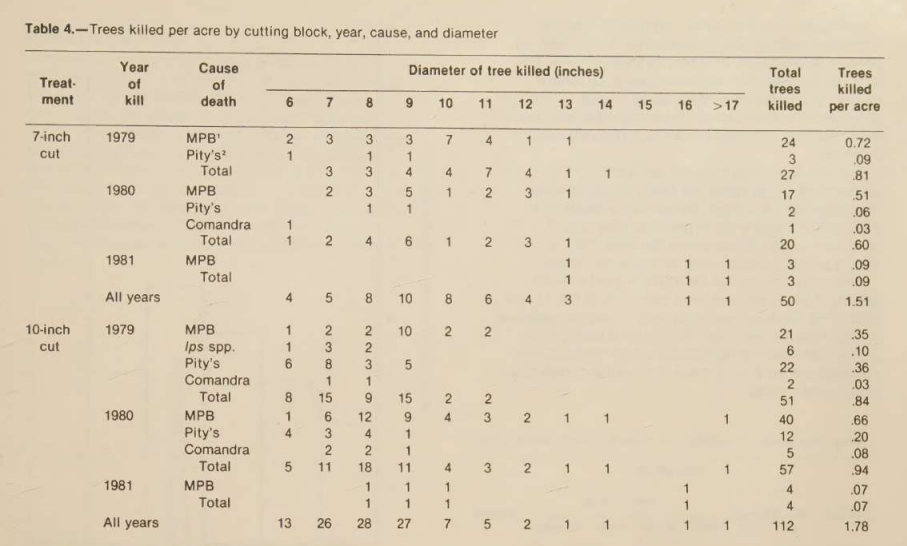
Scanned table titled 'Trees killed per acre by cutting block, year, cause, and diameter.'
On the complex scanned table, Nutrient lost structural boundaries as table complexity increased. Rows were clipped, some labels were misread, and the relationships between treatment, year, cause, diameter classes, and totals no longer held together.
Chart and visual-content handlingWeak: charts lose their semantics, and handwritten visual content is not retained.▾
Feature tested: Chart and visual-content handling
Result: Failed
Verdict: Weak: charts lose their semantics, and handwritten visual content is not retained.
Expected behavior: Nutrient did not meaningfully preserve non-text visuals in this research. For charts, it sometimes recovered some labels or values, but not the axes, series relationships, or chart structure that make the figure interpretable. For a scanned signatures page, it extracted surrounding text and signer details but did not capture the handwritten signature marks themselves.
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Waterfall chart showing SG&A rate movement from 2013 to 2015. — llamaparse-sga-rate-waterfall-chart-1.png
Observed output: Output artifact (Image): Nutrient recovered some numbers and labels from the waterfall chart, but did not reconstruct axes, legend relationships, or chart type information. The chart wa — nutirent_hybrid_earningspdf_parsed_waterfall_chart.png
Input artifact: Input artifact (Image): Waterfall chart showing SG&A rate movement from 2013 to 2015. — llamaparse-sga-rate-waterfall-chart-1.png
Output artifact: Output artifact (Image): Nutrient recovered some numbers and labels from the waterfall chart, but did not reconstruct axes, legend relationships, or chart type information. The chart wa — nutirent_hybrid_earningspdf_parsed_waterfall_chart.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Scanned line graph of average radial growth by cutting-block treatment from 1972 to 1981. — nutrient-io-figure-3-average-radial-growth-by-treatment.png
Observed output: Output artifact (Image): For the scanned line graph, Nutrient produced mostly garbled OCR text. The figure caption remained partly recognizable, but the plotted relationships and chart — nutrient-io-parsed-chart-forest-growth-cutting-blocks.png
Input artifact: Input artifact (Image): Scanned line graph of average radial growth by cutting-block treatment from 1972 to 1981. — nutrient-io-figure-3-average-radial-growth-by-treatment.png
Output artifact: Output artifact (Image): For the scanned line graph, Nutrient produced mostly garbled OCR text. The figure caption remained partly recognizable, but the plotted relationships and chart — nutrient-io-parsed-chart-forest-growth-cutting-blocks.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Scanned signatures page with handwritten signatures plus printed names and titles. — landing-ai-target-annual-report-signatures-page-2.png
Observed output: Output artifact (Image): On the scanned signatures page, Nutrient captured the heading, signer names, titles, and dates, but not the handwritten signature marks themselves. The output a — nutrient-io-target-signatures-ocr-extraction.png
Input artifact: Input artifact (Image): Scanned signatures page with handwritten signatures plus printed names and titles. — landing-ai-target-annual-report-signatures-page-2.png
Output artifact: Output artifact (Image): On the scanned signatures page, Nutrient captured the heading, signer names, titles, and dates, but not the handwritten signature marks themselves. The output a — nutrient-io-target-signatures-ocr-extraction.png
What changed: Image transformed into Image
Why it matters / Conclusion: If charts, figures, or handwritten marks matter to the fidelity of your markdown, Nutrient did not preserve them well enough in this test set.
Nutrient did not meaningfully preserve non-text visuals in this research. For charts, it sometimes recovered some labels or values, but not the axes, series relationships, or chart structure that make the figure interpretable. For a scanned signatures page, it extracted surrounding text and signer details but did not capture the handwritten signature marks themselves.
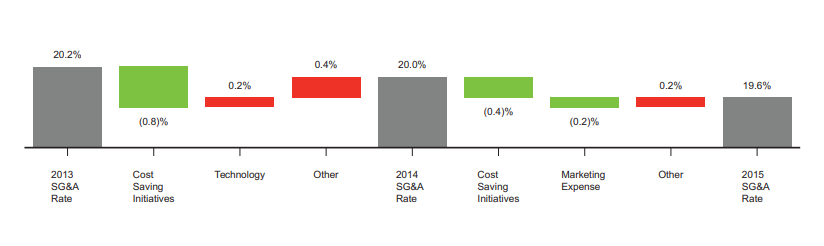
Waterfall chart showing SG&A rate movement from 2013 to 2015.

Nutrient recovered some numbers and labels from the waterfall chart, but did not reconstruct axes, legend relationships, or chart type information. The chart was reduced to ordinary text rather than preserved as a meaningful visual representation.
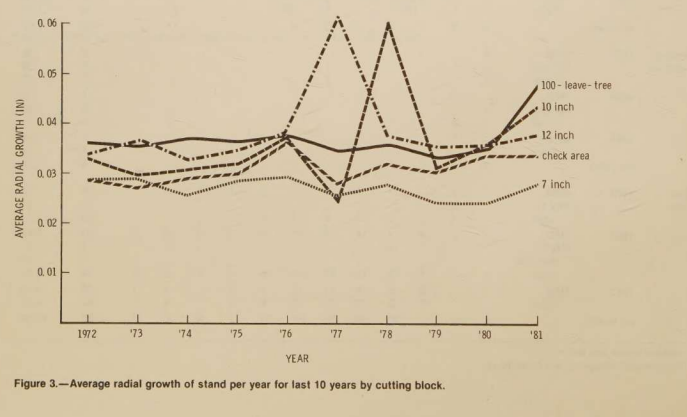
Scanned line graph of average radial growth by cutting-block treatment from 1972 to 1981.

For the scanned line graph, Nutrient produced mostly garbled OCR text. The figure caption remained partly recognizable, but the plotted relationships and chart layout were not preserved in usable form.

Scanned signatures page with handwritten signatures plus printed names and titles.
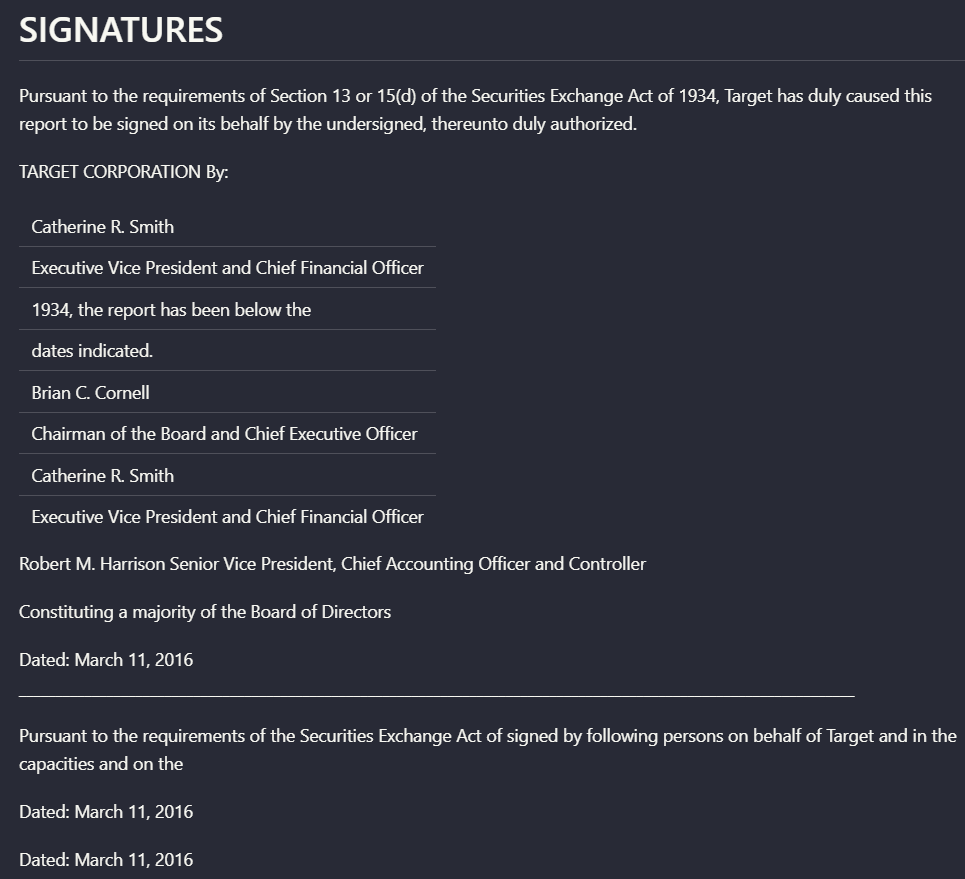
On the scanned signatures page, Nutrient captured the heading, signer names, titles, and dates, but not the handwritten signature marks themselves. The output also repeated some structured lines, reducing completeness and cleanliness.
Pricing & Access
Is This Right For You?
A side-by-side guide based on our hands-on testing.
Banner Preview
How the embed badge will look on your site

Embed HTML
Copy this code to your website source
Quick Integration Guide
- 1Copy the HTML code block above.
- 2Paste it into your site's HTML or CMS editor.
- 3Banner appears instantly on your page.
- 4Links back to your tool profile here.
Similar Tools
Discover more AI tools like Nutrient.io to enhance your workflow.