
Llamaparse
Reliable PDF-to-Markdown conversion for hybrid reports, with strong hierarchy and table capture but weaker preservation of complex table semantics and embedded visuals.
Good end-to-end markdown conversion, but not a perfect visual-preservation parser.
Across hybrid, financial, and scanned PDFs, Llamaparse reliably produced downloadable markdown and kept page-level reading order intact. It handled tables, charts, signatures, and scanned pages better than a basic text extractor, but complex grouped headers lost some semantic clarity and the table of contents flattened into sequential text. It is strongest when you want a hosted PDF-to-markdown pipeline, not when you need every visual element preserved as an image or every nested header relationship fully explicit.
In-Depth Review
Our detailed analysis of Llamaparse — features, performance, and real-world testing.
Feature-by-Feature Breakdown
Document Parsing to MarkdownAccepted all three complex PDFs and returned markdown exports without manual cleanup.▾
Feature tested: Document Parsing to Markdown
Result: Partial
Verdict: Accepted all three complex PDFs and returned markdown exports without manual cleanup.
Expected behavior: LlamaParse converts mixed PDFs and scanned documents into downloadable markdown, preserving readable order and headings on the hybrid earnings report, table-heavy financial report, and scanned research paper inputs.
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): Input — Hybrid-Earnings-PDF.pdf
Observed output: Output artifact (Text/code file): Accepted the 84-page hybrid annual report with native text, tables, charts, and a scanned signature page, and returned a markdown export. — llamaparse_target_earnings_output.md
Input artifact: Input artifact (PDF document): Input — Hybrid-Earnings-PDF.pdf
Output artifact: Output artifact (Text/code file): Accepted the 84-page hybrid annual report with native text, tables, charts, and a scanned signature page, and returned a markdown export. — llamaparse_target_earnings_output.md
What changed: PDF document transformed into Text/code file
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): Input — Sumitomo Financial PDF.pdf
Observed output: Output artifact (Text/code file): Accepted the table-heavy Sumitomo financial report and returned a markdown export. — llamaparse_financial_pdf_output.md
Input artifact: Input artifact (PDF document): Input — Sumitomo Financial PDF.pdf
Output artifact: Output artifact (Text/code file): Accepted the table-heavy Sumitomo financial report and returned a markdown export. — llamaparse_financial_pdf_output.md
What changed: PDF document transformed into Text/code file
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): Input — Scanned Research PDF.pdf
Observed output: Output artifact (Text/code file): Accepted the scanned research paper with multi-column text, tables, and charts and returned a markdown export. — llamaparse_scanned_pdf_output.md
Input artifact: Input artifact (PDF document): Input — Scanned Research PDF.pdf
Output artifact: Output artifact (Text/code file): Accepted the scanned research paper with multi-column text, tables, and charts and returned a markdown export. — llamaparse_scanned_pdf_output.md
What changed: PDF document transformed into Text/code file
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input — earnings_hybrid_pdf_input_page_3.png
Observed output: Output artifact (Image): Retained the Target annual report page's heading, paragraph, and bullet order as a readable text hierarchy instead of flattening it. — llamaparse_hybridInput_hierarchy.png
Input artifact: Input artifact (Image): Input — earnings_hybrid_pdf_input_page_3.png
Output artifact: Output artifact (Image): Retained the Target annual report page's heading, paragraph, and bullet order as a readable text hierarchy instead of flattening it. — llamaparse_hybridInput_hierarchy.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input — financialpdf_title_page.png
Observed output: Output artifact (Image): Preserved the Sumitomo report's title, disclaimer, and section ordering in a single reading flow. — llamaparse_financialInput_hierarchy.png
Input artifact: Input artifact (Image): Input — financialpdf_title_page.png
Output artifact: Output artifact (Image): Preserved the Sumitomo report's title, disclaimer, and section ordering in a single reading flow. — llamaparse_financialInput_hierarchy.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input — scanned_pdf_multicolumn_section.png
Observed output: Output artifact (Image): Turned a scanned two-column page into coherent single-column prose with the section flow intact. — llamaparse_scannedInput_hierarchy.png
Input artifact: Input artifact (Image): Input — scanned_pdf_multicolumn_section.png
Output artifact: Output artifact (Image): Turned a scanned two-column page into coherent single-column prose with the section flow intact. — llamaparse_scannedInput_hierarchy.png
What changed: Image transformed into Image
Why it matters / Conclusion: Strong at ingesting mixed PDF types end-to-end; the tool consistently produced a usable markdown result.
LlamaParse converts mixed PDFs and scanned documents into downloadable markdown, preserving readable order and headings on the hybrid earnings report, table-heavy financial report, and scanned research paper inputs.

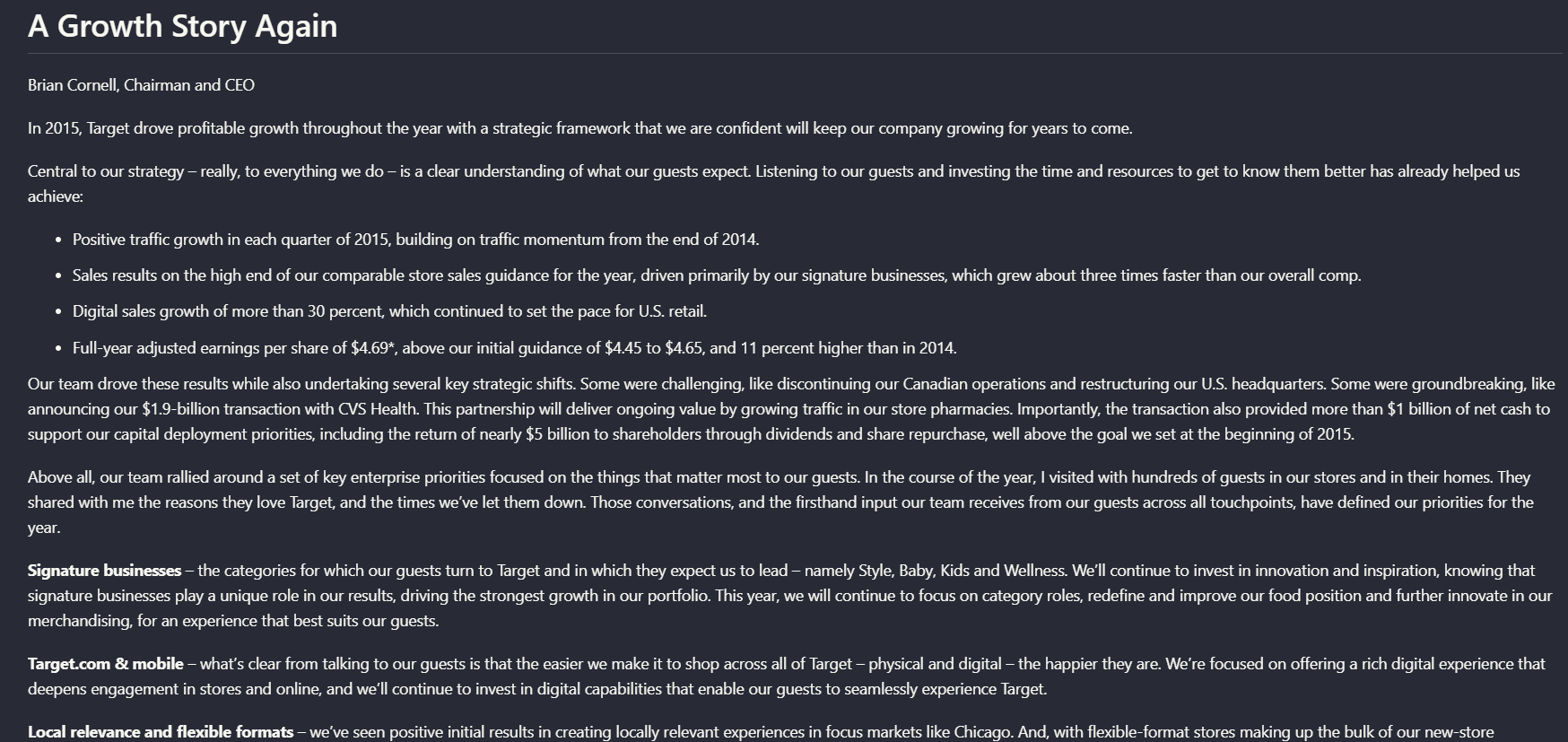

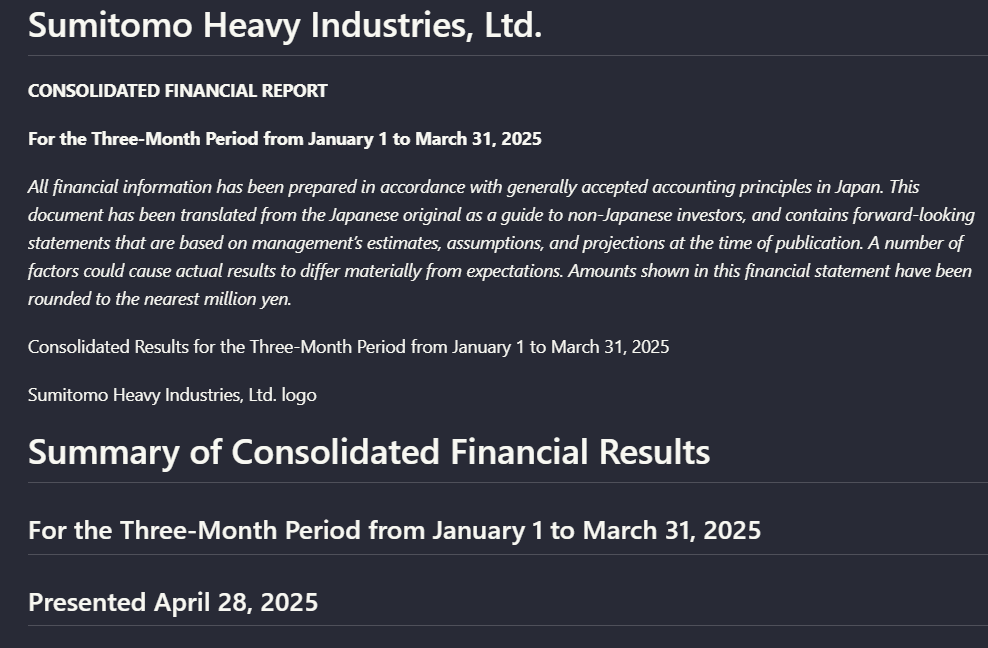


Table ExtractionProduces readable tables from financial, scanned, and nested table inputs, but grouped header semantics can drift.▾
Feature tested: Table Extraction
Result: Partial
Verdict: Produces readable tables from financial, scanned, and nested table inputs, but grouped header semantics can drift.
Expected behavior: LlamaParse reconstructs tables from digital and scanned documents, including financial tables, multi-level segment tables, and nested stand-data tables, with markdown-style table output.
Test case: Image → Image
Input type: Image
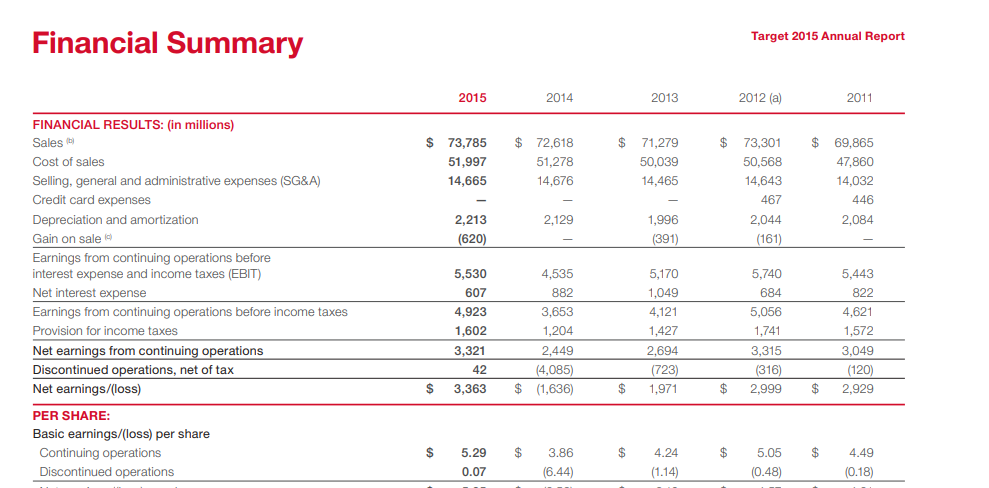
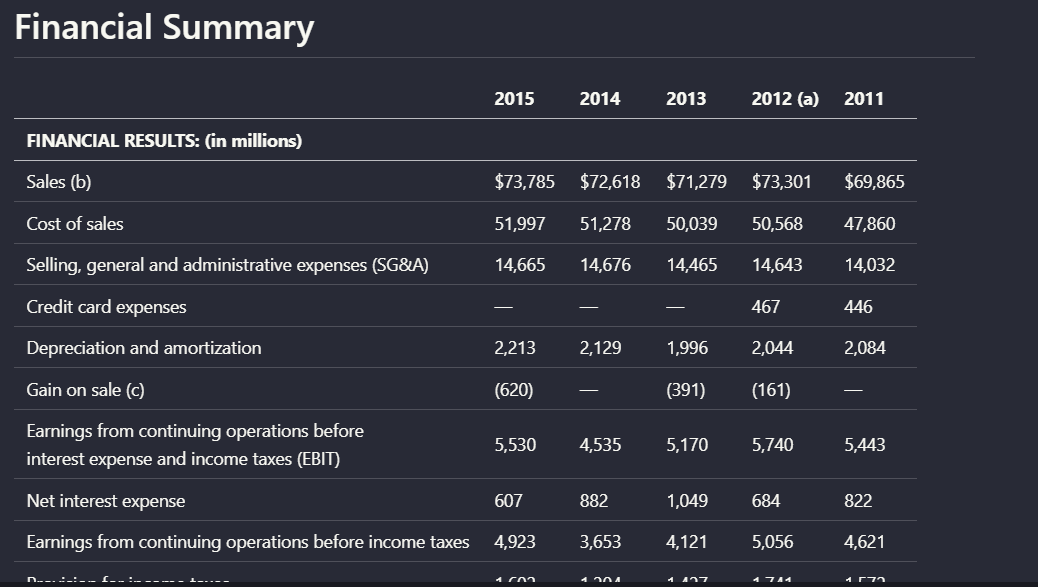
Input used: Input artifact (Image): Input — earnings_hybridInput_table.png
Observed output: Output artifact (Image): Preserved the financial summary table's rows, columns, and yearly values in a readable table. — Llamaparse_hybridInput_table_retention.png
Input artifact: Input artifact (Image): Input — earnings_hybridInput_table.png
Output artifact: Output artifact (Image): Preserved the financial summary table's rows, columns, and yearly values in a readable table. — Llamaparse_hybridInput_table_retention.png
What changed: Image transformed into Image
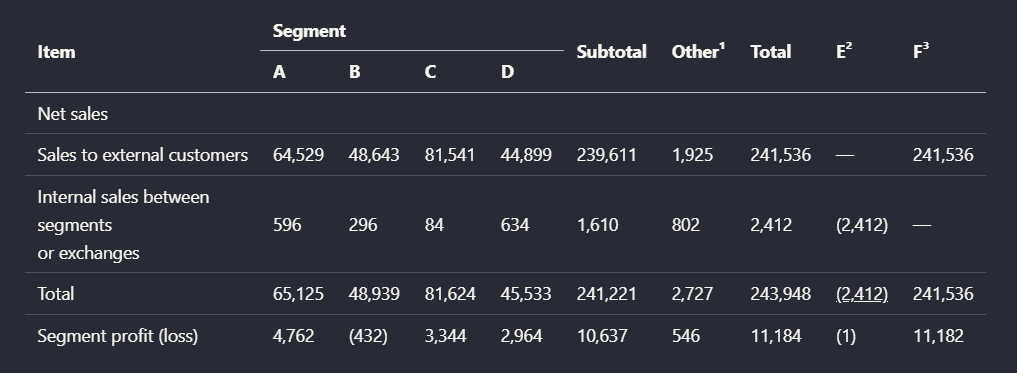
Test case: Image → Image
Input type: Image
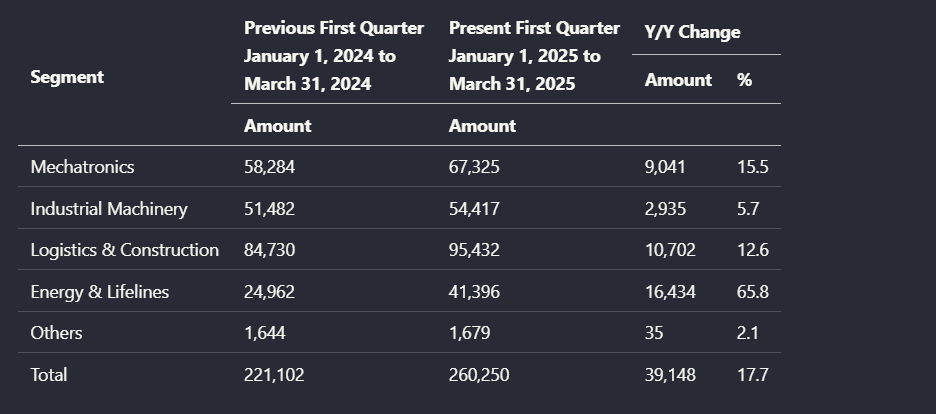
Input used: Input artifact (Image): Input — financial_pdf_multilevel_table.png
Observed output: Output artifact (Image): Preserved the grouped segment-results table and its year-over-year columns. — financialpdf_parsed_multilevel_table.png
Input artifact: Input artifact (Image): Input — financial_pdf_multilevel_table.png
Output artifact: Output artifact (Image): Preserved the grouped segment-results table and its year-over-year columns. — financialpdf_parsed_multilevel_table.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
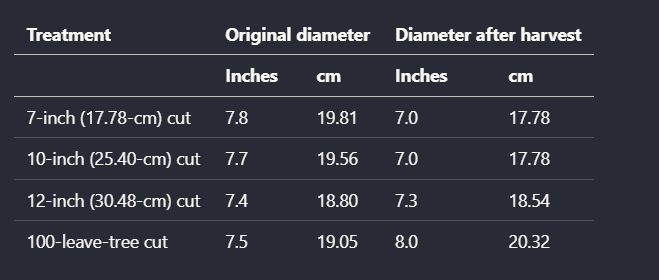
Input used: Input artifact (Image): Input — scanned_pdf_multicolumn_table.png
Observed output: Output artifact (Image): Cleaned up the scanned harvest-diameter table while keeping treatment rows and before/after values aligned. — llamaparse_scannedInput_table_retention.png
Input artifact: Input artifact (Image): Input — scanned_pdf_multicolumn_table.png
Output artifact: Output artifact (Image): Cleaned up the scanned harvest-diameter table while keeping treatment rows and before/after values aligned. — llamaparse_scannedInput_table_retention.png
What changed: Image transformed into Image
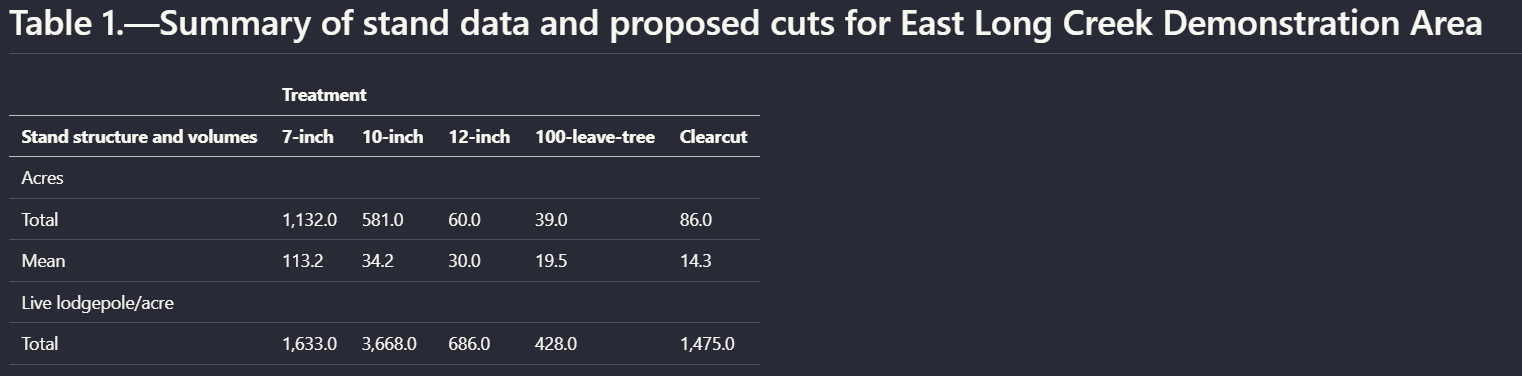
Test case: Image → Image
Input type: Image
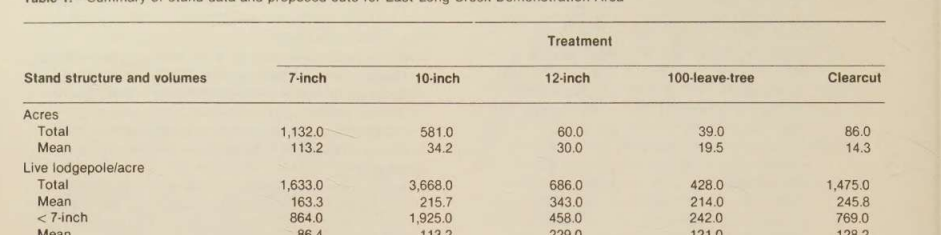
Input used: Input artifact (Image): Input — scanned_pdf_nested_table.png
Observed output: Output artifact (Image): Reconstructed the nested stand-data table with grouped treatment columns for 7-inch through clearcut cuts. — llamaparse_scannedInput_nested_table_outputmd.png
Input artifact: Input artifact (Image): Input — scanned_pdf_nested_table.png
Output artifact: Output artifact (Image): Reconstructed the nested stand-data table with grouped treatment columns for 7-inch through clearcut cuts. — llamaparse_scannedInput_nested_table_outputmd.png
What changed: Image transformed into Image
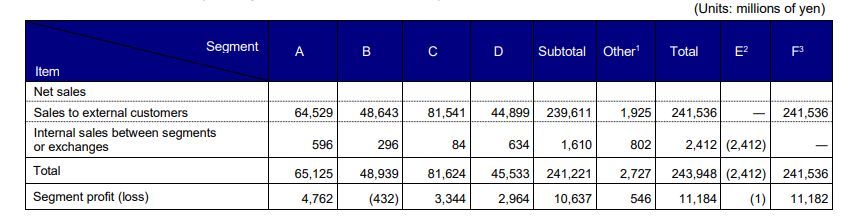
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input — financialInput_complex_table.png
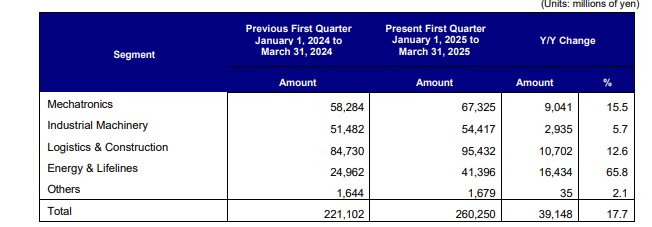
Observed output: Output artifact (Image): Preserved the segment sales table values, but the grouped column semantics became less explicit in the rebuilt version. — llamaparse_financialInput_parsed_table.png
Input artifact: Input artifact (Image): Input — financialInput_complex_table.png
Output artifact: Output artifact (Image): Preserved the segment sales table values, but the grouped column semantics became less explicit in the rebuilt version. — llamaparse_financialInput_parsed_table.png
What changed: Image transformed into Image
Why it matters / Conclusion: Readable table recovery is a strength, but complex grouped headers can lose some of their original structure and meaning.
LlamaParse reconstructs tables from digital and scanned documents, including financial tables, multi-level segment tables, and nested stand-data tables, with markdown-style table output.

OCR and Visual Content TranscriptionRecovers text from scans and transcribes charts/signatures, but does not keep visuals as visuals.▾
Feature tested: OCR and Visual Content Transcription
Result: Partial
Verdict: Recovers text from scans and transcribes charts/signatures, but does not keep visuals as visuals.
Expected behavior: LlamaParse transcribes visual content from PDFs, turning charts into structured tables or text sequences and recognizing blurry signatures/stamps instead of dropping them.
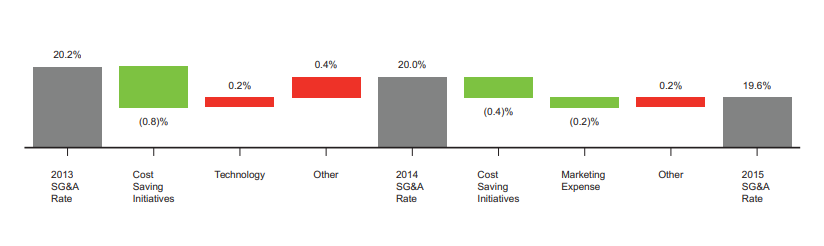
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input — hybridearnings_pdf_waterfall_chart.png
Observed output: Output artifact (Image): Converted the SG&A waterfall chart into a text sequence of rates and contributing changes instead of leaving it as an image. — llamaparse_hybrid_earningspdf_parsed_waterfall_chart.png
Input artifact: Input artifact (Image): Input — hybridearnings_pdf_waterfall_chart.png
Output artifact: Output artifact (Image): Converted the SG&A waterfall chart into a text sequence of rates and contributing changes instead of leaving it as an image. — llamaparse_hybrid_earningspdf_parsed_waterfall_chart.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input — hybrid_earningspdf_blurry_stamp.png
Observed output: Output artifact (Image): Detected the Ernst & Young LLP signature line from the blurry stamp and emitted it as extracted text rather than dropping it. — llamaparse_hybrid_earningspdf_parsed_blurry_stamp.png
Input artifact: Input artifact (Image): Input — hybrid_earningspdf_blurry_stamp.png
Output artifact: Output artifact (Image): Detected the Ernst & Young LLP signature line from the blurry stamp and emitted it as extracted text rather than dropping it. — llamaparse_hybrid_earningspdf_parsed_blurry_stamp.png
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
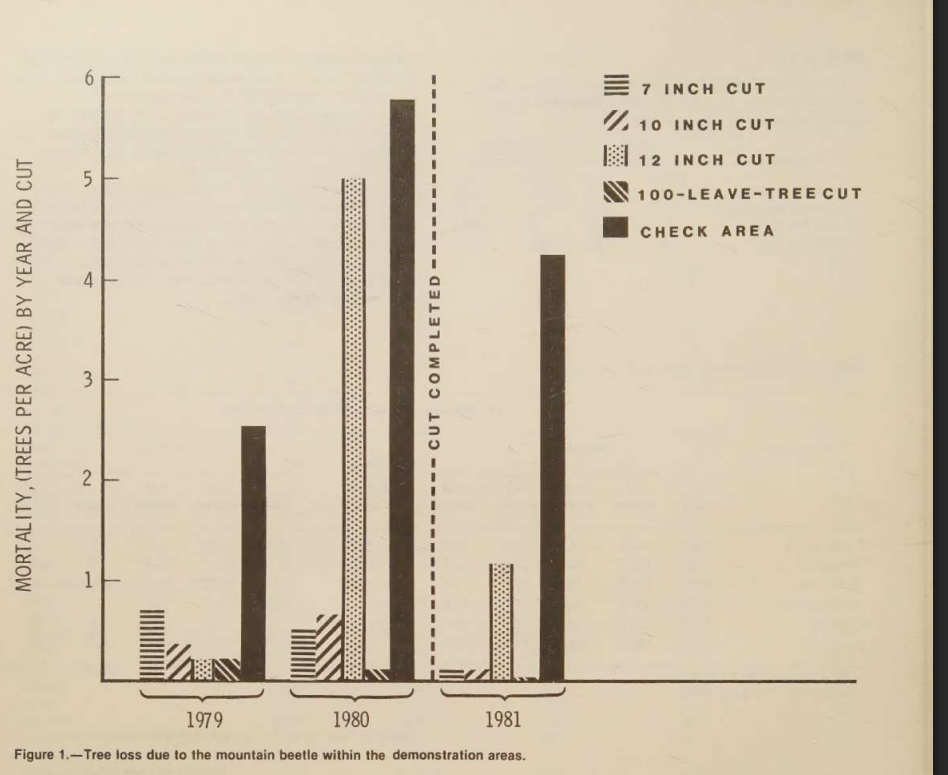
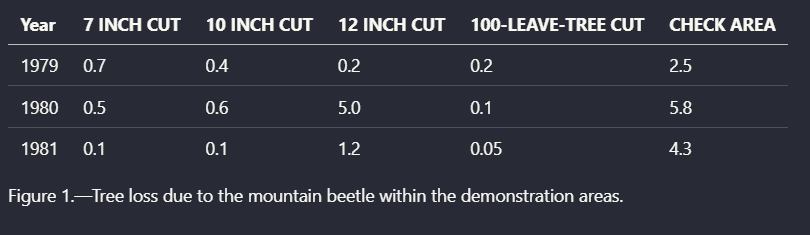
Input used: Input artifact (Image): Input — scanned_pdf_chart.png
Observed output: Output artifact (Image): Converted the scanned mortality chart into a structured year-by-treatment table. — llamaparse_scannedInput_parsed_chart.png
Input artifact: Input artifact (Image): Input — scanned_pdf_chart.png
Output artifact: Output artifact (Image): Converted the scanned mortality chart into a structured year-by-treatment table. — llamaparse_scannedInput_parsed_chart.png
What changed: Image transformed into Image
Why it matters / Conclusion: OCR and transcription coverage is good, but the output is text-centric rather than image-preserving.
LlamaParse transcribes visual content from PDFs, turning charts into structured tables or text sequences and recognizing blurry signatures/stamps instead of dropping them.


Hosted API AccessThe product is set up as a hosted service with API key management and a cloud results workflow.▾
Feature tested: Hosted API Access
Result: Passed
Verdict: The product is set up as a hosted service with API key management and a cloud results workflow.
Expected behavior: LlamaParse exposes project API keys, a results dashboard, and fully automated parsing through API calls, supporting cloud/API-backed workflows.
Test case: Text prompt → Image
Input type: Text prompt
Input used: Input artifact (Text prompt): INPUT
Observed output: Output artifact (Image): The settings page shows Project API Keys, existing keys, and a Generate New Key control for the hosted service. — llamaparse_apikey.png
Input artifact: Input artifact (Text prompt): INPUT
Output artifact: Output artifact (Image): The settings page shows Project API Keys, existing keys, and a Generate New Key control for the hosted service. — llamaparse_apikey.png
What changed: Text prompt transformed into Image
Test case: Text prompt → Image
Input type: Text prompt
Input used: Input artifact (Text prompt): INPUT
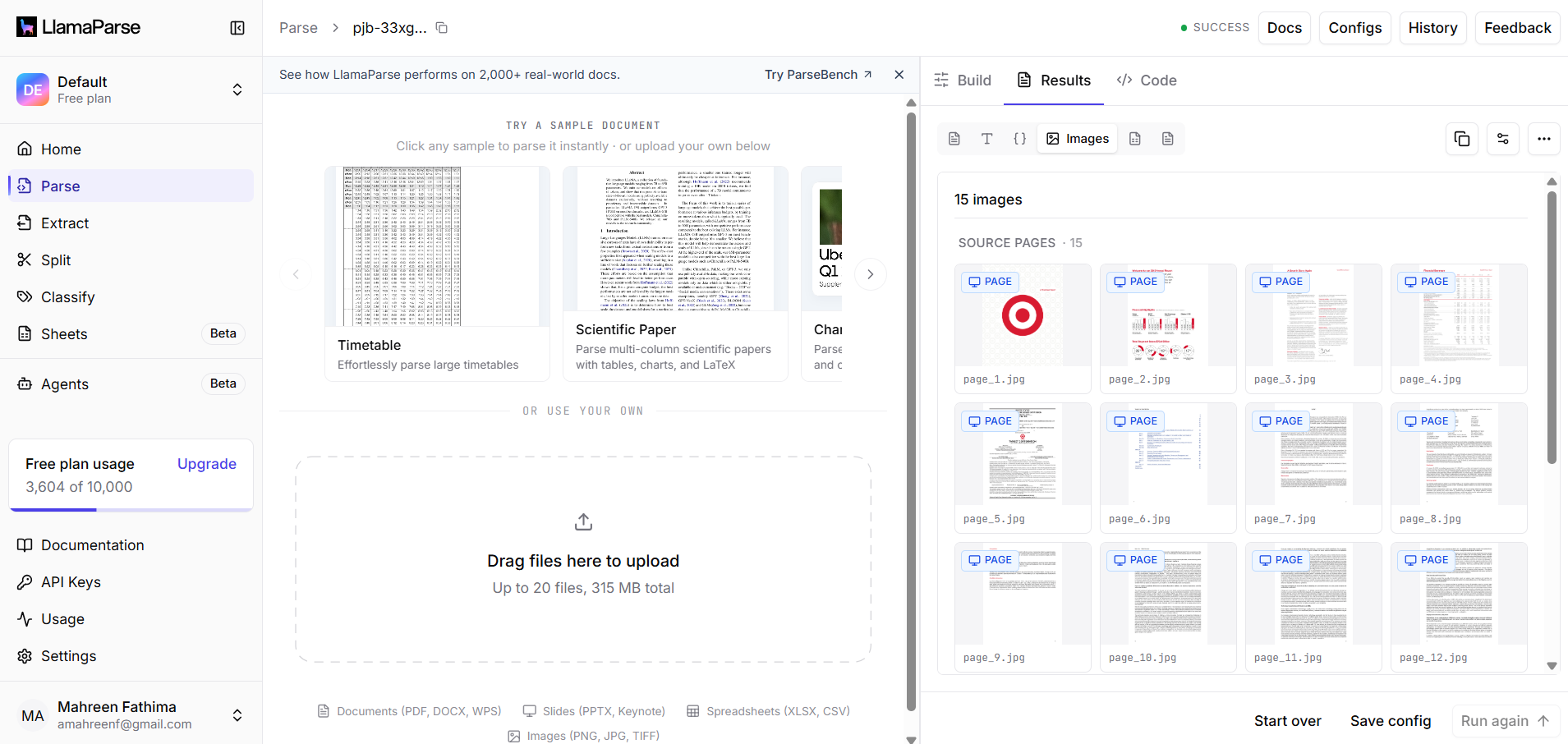
Observed output: Output artifact (Image): The web app shows Docs, Configs, History, Parse/Extract/Split/Classify navigation plus source-page thumbnails and result controls, confirming a hosted workflow. — llamaparse_downloadable_visual_assets.png
Input artifact: Input artifact (Text prompt): INPUT
Output artifact: Output artifact (Image): The web app shows Docs, Configs, History, Parse/Extract/Split/Classify navigation plus source-page thumbnails and result controls, confirming a hosted workflow. — llamaparse_downloadable_visual_assets.png
What changed: Text prompt transformed into Image
Why it matters / Conclusion: Well suited to API-backed pipelines, with visible credential management and a cloud results interface.
LlamaParse exposes project API keys, a results dashboard, and fully automated parsing through API calls, supporting cloud/API-backed workflows.
Resume ParsingExcellent — most structurally rich output of all tools tested, CGPA and certifications fully structured10/10▾
Feature tested: Resume Parsing
Result: Passed (10/10)
Verdict: Excellent — most structurally rich output of all tools tested, CGPA and certifications fully structured
Expected behavior: LlamaParse extracts structured fields from resumes across clean single-column, multi-column, and messy formats, returning rich JSON with skills, certifications, languages, projects, education, and related fields.
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): input-1-clean-resume-rugved.pdf — Llamaparse input.1.pdf
Observed output: Output artifact (Text/code file): Full JSON output — LlamaParse parsing clean resume — llama output.1.txt
Input artifact: Input artifact (PDF document): input-1-clean-resume-rugved.pdf — Llamaparse input.1.pdf
Output artifact: Output artifact (Text/code file): Full JSON output — LlamaParse parsing clean resume — llama output.1.txt
What changed: PDF document transformed into Text/code file
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): nput-2-multicolumn-resume-priya.pdf — Llamaparse input.2.pdf
Observed output: Output artifact (Text/code file): Full JSON output — LlamaParse parsing multi-column resume — llama output.2.txt
Input artifact: Input artifact (PDF document): nput-2-multicolumn-resume-priya.pdf — Llamaparse input.2.pdf
Output artifact: Output artifact (Text/code file): Full JSON output — LlamaParse parsing multi-column resume — llama output.2.txt
What changed: PDF document transformed into Text/code file
Test case: PDF document → Text/code file
Input type: PDF document
Input used: Input artifact (PDF document): input-3-messy-resume-john.pdf — Llamaparse input.3.pdf
Observed output: Output artifact (Text/code file): Full JSON output — LlamaParse parsing messy resume — llama output.3.txt
Input artifact: Input artifact (PDF document): input-3-messy-resume-john.pdf — Llamaparse input.3.pdf
Output artifact: Output artifact (Text/code file): Full JSON output — LlamaParse parsing messy resume — llama output.3.txt
What changed: PDF document transformed into Text/code file
Why it matters / Conclusion: Excellent output on clean resumes — most structurally rich of all tools tested. CGPA captured as dedicated standalone field. All 5 skill categories correctly structured. Both certifications as fully structured objects. Main weakness is job title missing the AI prefix and languages field absent since no spoken languages section was in the resume.
LlamaParse extracts structured fields from resumes across clean single-column, multi-column, and messy formats, returning rich JSON with skills, certifications, languages, projects, education, and related fields.
Pricing & Access
Pricing checked May 2026. We re-check quarterly. Credits are consumed per page based on selected parse tier. Visit llamaparse.ai for current plans.
Banner Preview
How the embed badge will look on your site

Embed HTML
Copy this code to your website source
Quick Integration Guide
- 1Copy the HTML code block above.
- 2Paste it into your site's HTML or CMS editor.
- 3Banner appears instantly on your page.
- 4Links back to your tool profile here.
Similar Tools
Discover more AI tools like Llamaparse to enhance your workflow.