
Leonardo AI Review: Tested Hands-On (2026)
A simple reference-image generator that creates polished new scenes, but it did not keep the same character reliably in this test.
Beautiful scenes, weak character lock
- You want attractive environments, outfits, and compositions from a single reference image.
- You can tolerate a polished lookalike instead of exact facial continuity.
- You value a simple upload-prompt-download workflow more than strict identity preservation.
- You need the same face to stay clearly recognizable across multiple scenes.
Feature scores on this page: 5.4/10 (5 scored features)
Our take
Leonardo AI was the weakest tool in this research for consistent characters. It reliably produced attractive environments, outfits, and compositions from a single reference image, but it repeatedly beautified and altered the face enough to break identity. The interrogation tests also exposed a tool-level weakness with emotional prompting: both "angry, guarded" scenes came back calm and neutral, and the near-profile stress test rotated the face so far away that identity could not be verified at all.
In-Depth Review
Our detailed analysis of Leonardo AI — features, performance, and real-world testing.
Feature-by-Feature Breakdown
Reference-based character consistencyLeonardo could restage a reference image into new scenes, but it did not preserve the same face reliably.4/10▾
Feature tested: Reference-based character consistency
Result: Failed (4/10)
Verdict: Leonardo could restage a reference image into new scenes, but it did not preserve the same face reliably.
Expected behavior: Leonardo's core capability here is generating new images from a single uploaded reference photo while changing the scene, pose, outfit, or environment. It was tested with a frontal portrait across a warm café close-up, desert horse-riding scene, and interrogation room; with a 3/4 restaurant portrait across interrogation room and street market scenes; and with a near-profile portrait in a rooftop golden-hour stress test.
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input 1 was a full frontal portrait with all facial features clearly visible. Prompted scene: a cozy warm café close-up with a braid, sweater, and natural seate — Input 1
Observed output: Output artifact (Image): Leonardo rendered the café environment, warm mood, sweater, braid, and pose cleanly, but the face changed enough to read as a lookalike rather than the same per — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input1-warm-cafe.jpg
Input artifact: Input artifact (Image): Input 1 was a full frontal portrait with all facial features clearly visible. Prompted scene: a cozy warm café close-up with a braid, sweater, and natural seate — Input 1
Output artifact: Output artifact (Image): Leonardo rendered the café environment, warm mood, sweater, braid, and pose cleanly, but the face changed enough to read as a lookalike rather than the same per — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input1-warm-cafe.jpg
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): The same Input 1 frontal portrait was used. Prompted scene: a desert horse-riding image at sunset with action, outfit change, and a cinematic environment. — Input 1-1.Input 1
Observed output: Output artifact (Image): Leonardo produced a detailed desert setting, correct horse-riding action, and strong cinematic composition, but the subject no longer resembled the reference in — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input1-horseride.jpg
Input artifact: Input artifact (Image): The same Input 1 frontal portrait was used. Prompted scene: a desert horse-riding image at sunset with action, outfit change, and a cinematic environment. — Input 1-1.Input 1
Output artifact: Output artifact (Image): Leonardo produced a detailed desert setting, correct horse-riding action, and strong cinematic composition, but the subject no longer resembled the reference in — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input1-horseride.jpg
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input 2 was a 3/4 restaurant portrait with softer lighting and partially hidden facial detail. Prompted scene: a crowded street market with a sari, walking pose — Input 2-3.Input 2
Observed output: Output artifact (Image): Leonardo handled the market environment, sari styling, walking pose, and overall realism well. Hair volume stayed closer to the reference here than in other sce — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input2-market.jpg
Input artifact: Input artifact (Image): Input 2 was a 3/4 restaurant portrait with softer lighting and partially hidden facial detail. Prompted scene: a crowded street market with a sari, walking pose — Input 2-3.Input 2
Output artifact: Output artifact (Image): Leonardo handled the market environment, sari styling, walking pose, and overall realism well. Hair volume stayed closer to the reference here than in other sce — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input2-market.jpg
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input 3 was a near-profile portrait with one eye partly occluded and the face turned roughly 80-90 degrees. Prompted scene: rooftop golden hour, black top, beig — input 3.webp
Observed output: Output artifact (Image): Leonardo followed the rooftop setting, outfit, skyline, golden-hour lighting, and full-body pose instructions, but it rotated the face too far away from camera. — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input3-rooftop.jpg
Input artifact: Input artifact (Image): Input 3 was a near-profile portrait with one eye partly occluded and the face turned roughly 80-90 degrees. Prompted scene: rooftop golden hour, black top, beig — input 3.webp
Output artifact: Output artifact (Image): Leonardo followed the rooftop setting, outfit, skyline, golden-hour lighting, and full-body pose instructions, but it rotated the face too far away from camera. — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input3-rooftop.jpg
What changed: Image transformed into Image
Why it matters / Conclusion: Leonardo was good at making attractive scene variations from one image, but not at keeping the same person recognizably intact across those variations.
Leonardo's core capability here is generating new images from a single uploaded reference photo while changing the scene, pose, outfit, or environment. It was tested with a frontal portrait across a warm café close-up, desert horse-riding scene, and interrogation room; with a 3/4 restaurant portrait across interrogation room and street market scenes; and with a near-profile portrait in a rooftop golden-hour stress test.
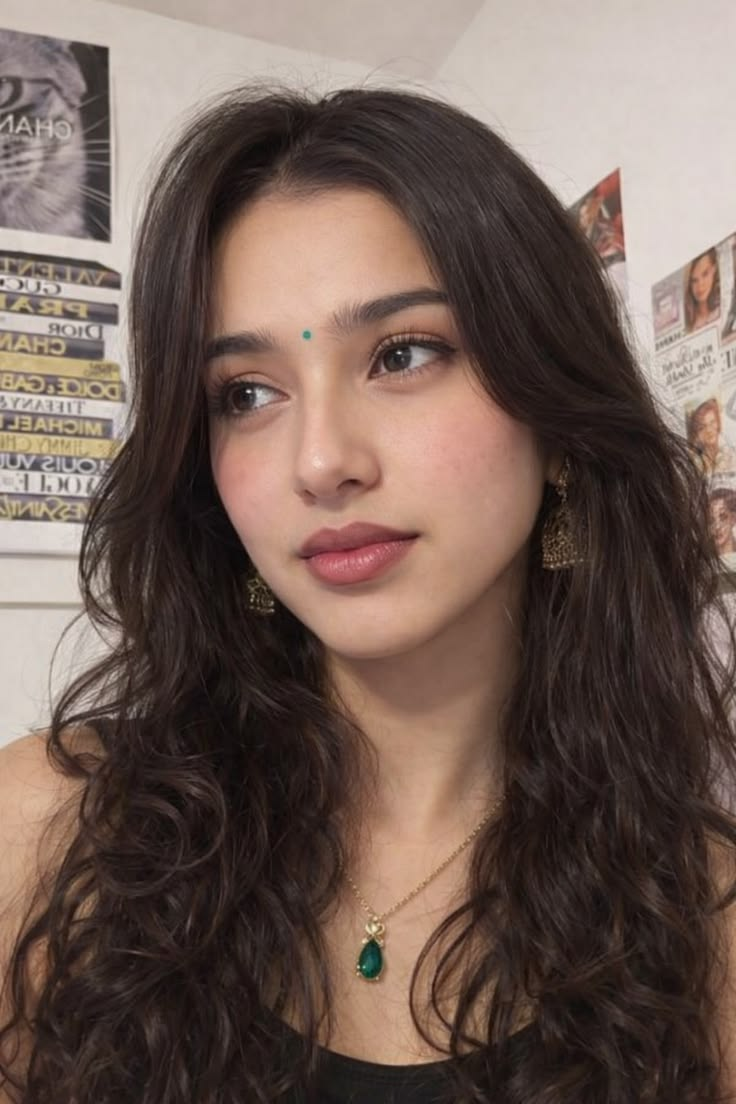
Input 1 was a full frontal portrait with all facial features clearly visible. Prompted scene: a cozy warm café close-up with a braid, sweater, and natural seated pose.

Leonardo rendered the café environment, warm mood, sweater, braid, and pose cleanly, but the face changed enough to read as a lookalike rather than the same person. Natural curls from the reference were replaced with smoother, more stylized hair, and the skin was polished into a commercial-photo look.
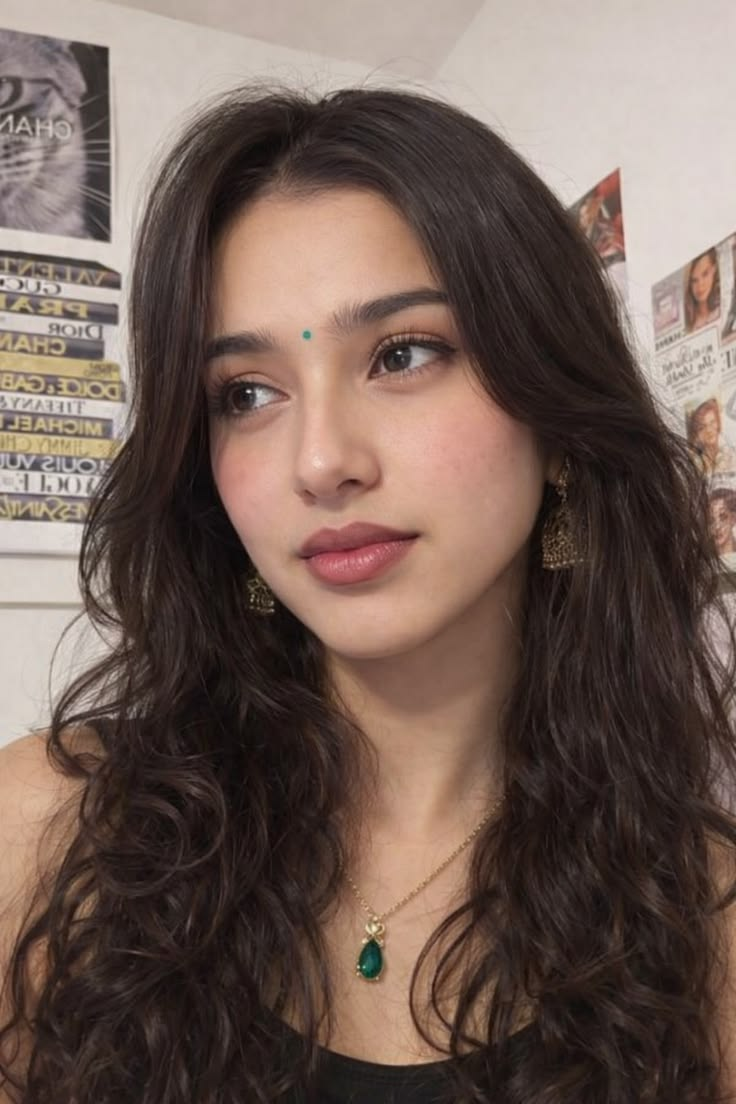
The same Input 1 frontal portrait was used. Prompted scene: a desert horse-riding image at sunset with action, outfit change, and a cinematic environment.

Leonardo produced a detailed desert setting, correct horse-riding action, and strong cinematic composition, but the subject no longer resembled the reference in face shape, proportions, or overall identity. The result reads as a different fantasy character rather than the same person in a new scene.

Input 2 was a 3/4 restaurant portrait with softer lighting and partially hidden facial detail. Prompted scene: a crowded street market with a sari, walking pose, and lively environment.

Leonardo handled the market environment, sari styling, walking pose, and overall realism well. Hair volume stayed closer to the reference here than in other scenes, but the face is turned away enough that full identity verification is difficult, so this was only a partial success for character consistency.

Input 3 was a near-profile portrait with one eye partly occluded and the face turned roughly 80-90 degrees. Prompted scene: rooftop golden hour, black top, beige trousers, full-body pose with both arms raised.

Leonardo followed the rooftop setting, outfit, skyline, golden-hour lighting, and full-body pose instructions, but it rotated the face too far away from camera. Almost no usable facial detail remained, so the test's core requirement—keeping a difficult near-profile identity still recognizable—was unmet.
Expression and atmosphere controlLeonardo repeatedly missed emotionally intense prompts and defaulted to calm, polished portraits.3/10▾
Feature tested: Expression and atmosphere control
Result: Failed (3/10)
Verdict: Leonardo repeatedly missed emotionally intense prompts and defaulted to calm, polished portraits.
Expected behavior: This capability was tested by giving Leonardo the same interrogation-room prompt with two different reference images. The goal was to see whether it could preserve identity while also delivering an angry, guarded expression and harsh institutional lighting.
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input 1 was a full frontal portrait. Prompted scene: interrogation room with formal clothing, harsh overhead lighting, and an angry, guarded expression. — Input 1-2.Input 1
Observed output: Output artifact (Image): This was Leonardo's best identity result from Input 1: the face remained broadly recognizable. But the core emotional instruction failed. The subject looks calm — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input1-interrogation.jpg
Input artifact: Input artifact (Image): Input 1 was a full frontal portrait. Prompted scene: interrogation room with formal clothing, harsh overhead lighting, and an angry, guarded expression. — Input 1-2.Input 1
Output artifact: Output artifact (Image): This was Leonardo's best identity result from Input 1: the face remained broadly recognizable. But the core emotional instruction failed. The subject looks calm — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input1-interrogation.jpg
What changed: Image transformed into Image
Test case: Image → Image
Input type: Image
Input used: Input artifact (Image): Input 2 was a 3/4 warm indoor portrait. Prompted scene: the same interrogation-room setup with the same angry, guarded expression request. — Input 2-4.Input 2
Observed output: Output artifact (Image): Leonardo again returned a neutral expression instead of the requested intensity, confirming the miss was not specific to one reference image. The room reads mor — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input2-interrogation.jpg
Input artifact: Input artifact (Image): Input 2 was a 3/4 warm indoor portrait. Prompted scene: the same interrogation-room setup with the same angry, guarded expression request. — Input 2-4.Input 2
Output artifact: Output artifact (Image): Leonardo again returned a neutral expression instead of the requested intensity, confirming the miss was not specific to one reference image. The room reads mor — best-ai-tools-to-generate-consistent-characters-ac-leonardo-input2-interrogation.jpg
What changed: Image transformed into Image
Why it matters / Conclusion: Across two different references, Leonardo failed the same emotional prompt in the same way, which points to a tool-level limitation in expression control.
This capability was tested by giving Leonardo the same interrogation-room prompt with two different reference images. The goal was to see whether it could preserve identity while also delivering an angry, guarded expression and harsh institutional lighting.
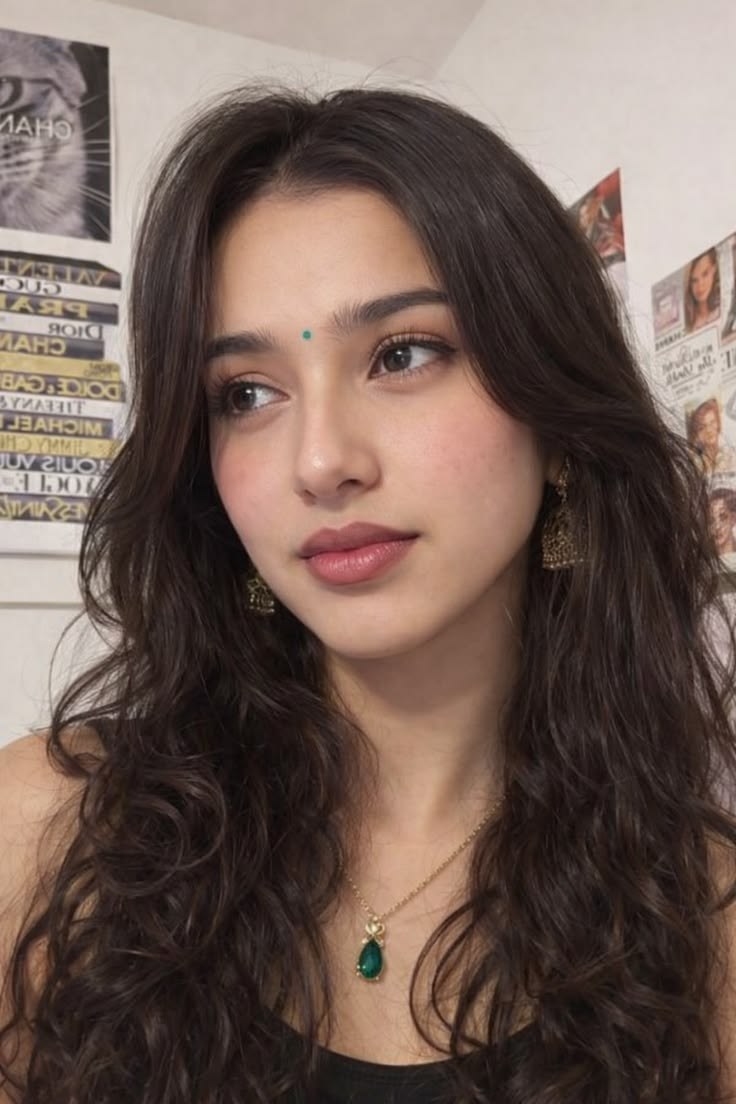
Input 1 was a full frontal portrait. Prompted scene: interrogation room with formal clothing, harsh overhead lighting, and an angry, guarded expression.

This was Leonardo's best identity result from Input 1: the face remained broadly recognizable. But the core emotional instruction failed. The subject looks calm and neutral rather than angry or guarded, the room is too neat, and the lighting lacks the harsh institutional feel described in the prompt.

Input 2 was a 3/4 warm indoor portrait. Prompted scene: the same interrogation-room setup with the same angry, guarded expression request.

Leonardo again returned a neutral expression instead of the requested intensity, confirming the miss was not specific to one reference image. The room reads more like a bright office than an interrogation setting, and the reference's dense natural curls were flattened into straighter, oilier-looking hair.
Image-to-Cinematic Video Generation (2D)Strong — smooth motion and stable rendering7.5/10▾
Feature tested: Image-to-Cinematic Video Generation (2D)
Result: Passed (7.5/10)
Verdict: Strong — smooth motion and stable rendering
Expected behavior: Transforms static 2D illustrations into cinematic animated clips with smooth camera movement and visually stable rendering.
Test case: Image → Video file
Input type: Image
Input used: Input artifact (Image): Slow cinematic close-up of a smiling girl holding clover leaves in a spring garden. Her hair flows in the breeze as cherry blossom petals drift around her and s — 2d image-2.jpg
Observed output: Output artifact (Video file): Output: Cinematic animated clip — motion_2.0-fast_Slow_cinematic_push-in_camera_movement_with_a_shallow_depth_of_field_softly_focu-0.mp4
Input artifact: Input artifact (Image): Slow cinematic close-up of a smiling girl holding clover leaves in a spring garden. Her hair flows in the breeze as cherry blossom petals drift around her and s — 2d image-2.jpg
Output artifact: Output artifact (Video file): Output: Cinematic animated clip — motion_2.0-fast_Slow_cinematic_push-in_camera_movement_with_a_shallow_depth_of_field_softly_focu-0.mp4
What changed: Image transformed into Video file
Why it matters / Conclusion: The animation holds through the clip — but pause at the 4-second mark to check the hands against what the prompt asked for, and watch the environmental motion with sound on; the silence behind the bush movement is what actually lowers the cinematic feel here.
Transforms static 2D illustrations into cinematic animated clips with smooth camera movement and visually stable rendering.

Slow cinematic close-up of a smiling girl holding clover leaves in a spring garden. Her hair flows in the breeze as cherry blossom petals drift around her and soft sunlight flickers through the trees. Warm, dreamy Studio Ghibli atmosphere with smooth, natural motion.
Cinematic Animation from 3D ScenesAverage — smooth movement but realism inconsistency6.5/10▾
Feature tested: Cinematic Animation from 3D Scenes
Result: Passed (6.5/10)
Verdict: Average — smooth movement but realism inconsistency
Expected behavior: Animates cinematic 3D scenes with environmental motion and cinematic transitions.
Test case: Image → Video file
Input type: Image
Input used: Input artifact (Image): Slow cinematic dolly through a lively street market at sunset. People interact naturally, a donkey cart moves through the center, palm trees sway, birds fly ove — 3d image-1.png
Observed output: Output artifact (Video file): Output: Animated 3D cinematic scene — motion_2.0-fast_Slow_cinematic_forward_dolly_through_the_street_with_warm_golden_hour_lighting._-0.mp4
Input artifact: Input artifact (Image): Slow cinematic dolly through a lively street market at sunset. People interact naturally, a donkey cart moves through the center, palm trees sway, birds fly ove — 3d image-1.png
Output artifact: Output artifact (Video file): Output: Animated 3D cinematic scene — motion_2.0-fast_Slow_cinematic_forward_dolly_through_the_street_with_warm_golden_hour_lighting._-0.mp4
What changed: Image transformed into Video file
Why it matters / Conclusion: The sunset sky stays visible throughout — but the birds mentioned in the prompt never appear at any point; and while the crowd motion looks natural overall, watch the two figures on the left footpath in the first 3 seconds — their walk breaks the scene in a way the wider crowd masks, and pause on the cart rider's face to see where the feature loss actually lands.
Animates cinematic 3D scenes with environmental motion and cinematic transitions.

Slow cinematic dolly through a lively street market at sunset. People interact naturally, a donkey cart moves through the center, palm trees sway, birds fly overhead, and the setting sun casts warm golden light and long shadows.
Realistic Image AnimationModerate — stable motion but weak realism6/10▾
Feature tested: Realistic Image Animation
Result: Passed (6/10)
Verdict: Moderate — stable motion but weak realism
Expected behavior: Generates cinematic animation from realistic wildlife and photography-style images.
Test case: Image → Video file
Input type: Image
Input used: Input artifact (Image): Slow cinematic push-in on a majestic tiger walking toward a rock at sunset. After settling into a dominant pose, the tiger breathes calmly, then lets out a powe — realistic image-1.jpeg
Observed output: Output artifact (Video file): Output: Realistic animated wildlife clip — motion_2.0-fast_Slow_cinematic_push-in_toward_the_tiger_with_strong_focus_and_shallow_depth_of_f-0.mp4
Input artifact: Input artifact (Image): Slow cinematic push-in on a majestic tiger walking toward a rock at sunset. After settling into a dominant pose, the tiger breathes calmly, then lets out a powe — realistic image-1.jpeg
Output artifact: Output artifact (Video file): Output: Realistic animated wildlife clip — motion_2.0-fast_Slow_cinematic_push-in_toward_the_tiger_with_strong_focus_and_shallow_depth_of_f-0.mp4
What changed: Image transformed into Video file
Why it matters / Conclusion: Compare the realistic input image to the output — then watch the first 3 seconds to see where the realism actually lands.
Generates cinematic animation from realistic wildlife and photography-style images.

Slow cinematic push-in on a majestic tiger walking toward a rock at sunset. After settling into a dominant pose, the tiger breathes calmly, then lets out a powerful roar as clouds drift and trees sway in the warm evening breeze.
Free version tested
The report only documented Leonardo's free-credit usage, not full paid-plan pricing.
Research notes: 150 credits per day on the free version, with 40 credits per generation.
Is This Right For You?
A side-by-side guide based on our hands-on testing.
Banner Preview
How the embed badge will look on your site

Embed HTML
Copy this code to your website source
Quick Integration Guide
- 1Copy the HTML code block above.
- 2Paste it into your site's HTML or CMS editor.
- 3Banner appears instantly on your page.
- 4Links back to your tool profile here.
Similar Tools
Discover more AI tools like Leonardo AI to enhance your workflow.