Firecrawl
Reliable on JavaScript-heavy and bot-protected pages, but its markdown output usually needs a cleanup step.
Strong access, weak extraction cleanup
Firecrawl performed well at the hard part of web extraction: it scraped a static recipe page, a JavaScript-hydrated Nike product page, and a Glassdoor jobs page behind anti-bot protections without manual selectors. The tradeoff is that its output behaved more like a flattened DOM dump than a semantically cleaned extraction, repeatedly mixing useful content with navigation, footer links, filters, and other page chrome. It looks best suited for pipelines that already include a downstream LLM or parser to clean the markdown.
In-Depth Review
Our detailed analysis of Firecrawl — features, performance, and real-world testing.
Feature-by-Feature Breakdown
Single-URL page scraping to MarkdownIt preserved article text and markdown structure, but did not meaningfully filter site boilerplate.▾
Feature tested: Single-URL page scraping to Markdown
Result: Passed
Verdict: It preserved article text and markdown structure, but did not meaningfully filter site boilerplate.
Expected behavior: Firecrawl can take a public URL and return a Markdown version of the page without manual CSS selection. This was tested on Sally’s Baking Addiction’s chewy chocolate chip cookies page, where it preserved the article’s textual structure, including headings, lists, and linked sections, but also pulled large amounts of navigation, sidebar, review, and footer content into the same output.
Test case: Text prompt → Image
Input type: Text prompt
Input used: Input artifact (Text prompt): Recipe blog URL
Observed output: Output artifact (Image): Firecrawl returned a successful Markdown scrape of the Sally’s Baking Addiction recipe page. The output preserved the page title, heading structure, links, ingr — firecrawl-firecrawl-scrape-dashboard-nike-page.png
Input artifact: Input artifact (Text prompt): Recipe blog URL
Output artifact: Output artifact (Image): Firecrawl returned a successful Markdown scrape of the Sally’s Baking Addiction recipe page. The output preserved the page title, heading structure, links, ingr — firecrawl-firecrawl-scrape-dashboard-nike-page.png
What changed: Text prompt transformed into Image
Why it matters / Conclusion: Good raw Markdown conversion from a public URL, weak semantic cleanup.
Firecrawl can take a public URL and return a Markdown version of the page without manual CSS selection. This was tested on Sally’s Baking Addiction’s chewy chocolate chip cookies page, where it preserved the article’s textual structure, including headings, lists, and linked sections, but also pulled large amounts of navigation, sidebar, review, and footer content into the same output.
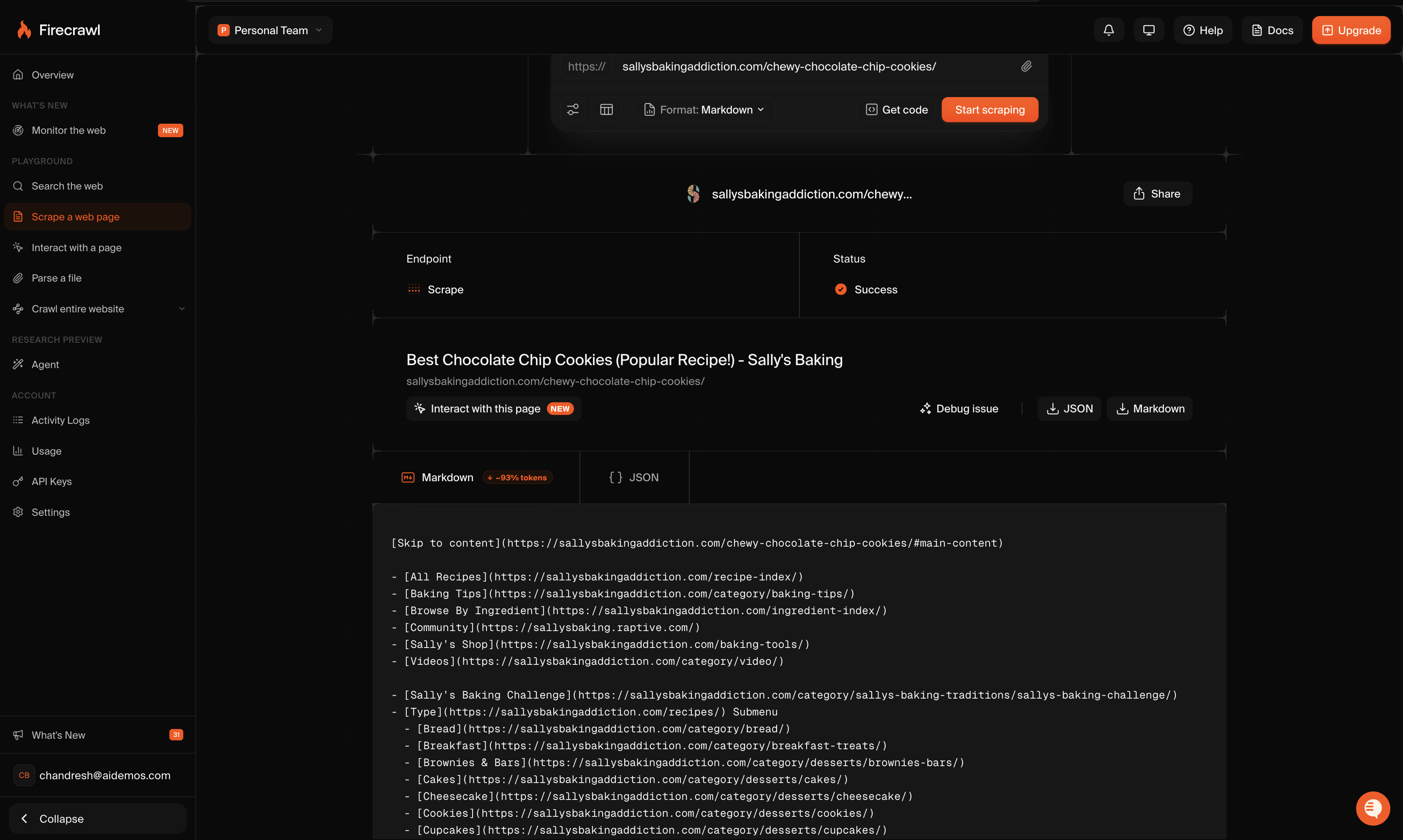
Firecrawl returned a successful Markdown scrape of the Sally’s Baking Addiction recipe page. The output preserved the page title, heading structure, links, ingredients, and recipe flow, but it also included major site-wide navigation items, category links, and other boilerplate instead of isolating only the main article body.
JavaScript-rendered page extractionHydration worked, but cleanup did not.▾
Feature tested: JavaScript-rendered page extraction
Result: Partial
Verdict: Hydration worked, but cleanup did not.
Expected behavior: Renders client-side JavaScript before extraction. On a Nike single-page product experience, Firecrawl waited for the page to hydrate and successfully captured the product title, price, and the full dynamically loaded size range from M 5 / W 6.5 through M 18 / W 19.5. The output still included raw code artifacts, media attachment matrices, localization links, and image URL trees.
Test case: Text prompt → Text prompt
Input type: Text prompt
Input used: Input artifact (Text prompt): Nike SPA product URL
Observed output: Output artifact (Text prompt): Observed result
Input artifact: Input artifact (Text prompt): Nike SPA product URL
Output artifact: Output artifact (Text prompt): Observed result
What changed: Text prompt transformed into Text prompt
Why it matters / Conclusion: Reliable for pulling data that only appears after hydration, but the returned Markdown is still noisy and messy.
Renders client-side JavaScript before extraction. On a Nike single-page product experience, Firecrawl waited for the page to hydrate and successfully captured the product title, price, and the full dynamically loaded size range from M 5 / W 6.5 through M 18 / W 19.5. The output still included raw code artifacts, media attachment matrices, localization links, and image URL trees.
JavaScript-rendered page extractionIt successfully waited for client-side rendering and captured dynamic product details, but the final Markdown remained cluttered.▾
Feature tested: JavaScript-rendered page extraction
Result: Passed
Verdict: It successfully waited for client-side rendering and captured dynamic product details, but the final Markdown remained cluttered.
Expected behavior: Firecrawl can scrape pages that rely on client-side JavaScript hydration. This was tested on a Nike Air Force 1 product page, where it captured dynamic product details and the full size run after rendering, showing that the tool waited for the page’s JavaScript state to load before extracting content.
Test case: Text prompt → Image
Input type: Text prompt
Input used: Input artifact (Text prompt): Dynamic product page URL
Observed output: Output artifact (Image): Firecrawl returned a successful Markdown scrape of the Nike product page with the rendered product title and key sections such as Size & Fit and Shipping & Retu — firecrawl-firecrawl-nike-scrape-markdown-output.png
Input artifact: Input artifact (Text prompt): Dynamic product page URL
Output artifact: Output artifact (Image): Firecrawl returned a successful Markdown scrape of the Nike product page with the rendered product title and key sections such as Size & Fit and Shipping & Retu — firecrawl-firecrawl-nike-scrape-markdown-output.png
What changed: Text prompt transformed into Image
Why it matters / Conclusion: Strong JS rendering support, but not strong content cleanup.
Firecrawl can scrape pages that rely on client-side JavaScript hydration. This was tested on a Nike Air Force 1 product page, where it captured dynamic product details and the full size run after rendering, showing that the tool waited for the page’s JavaScript state to load before extracting content.
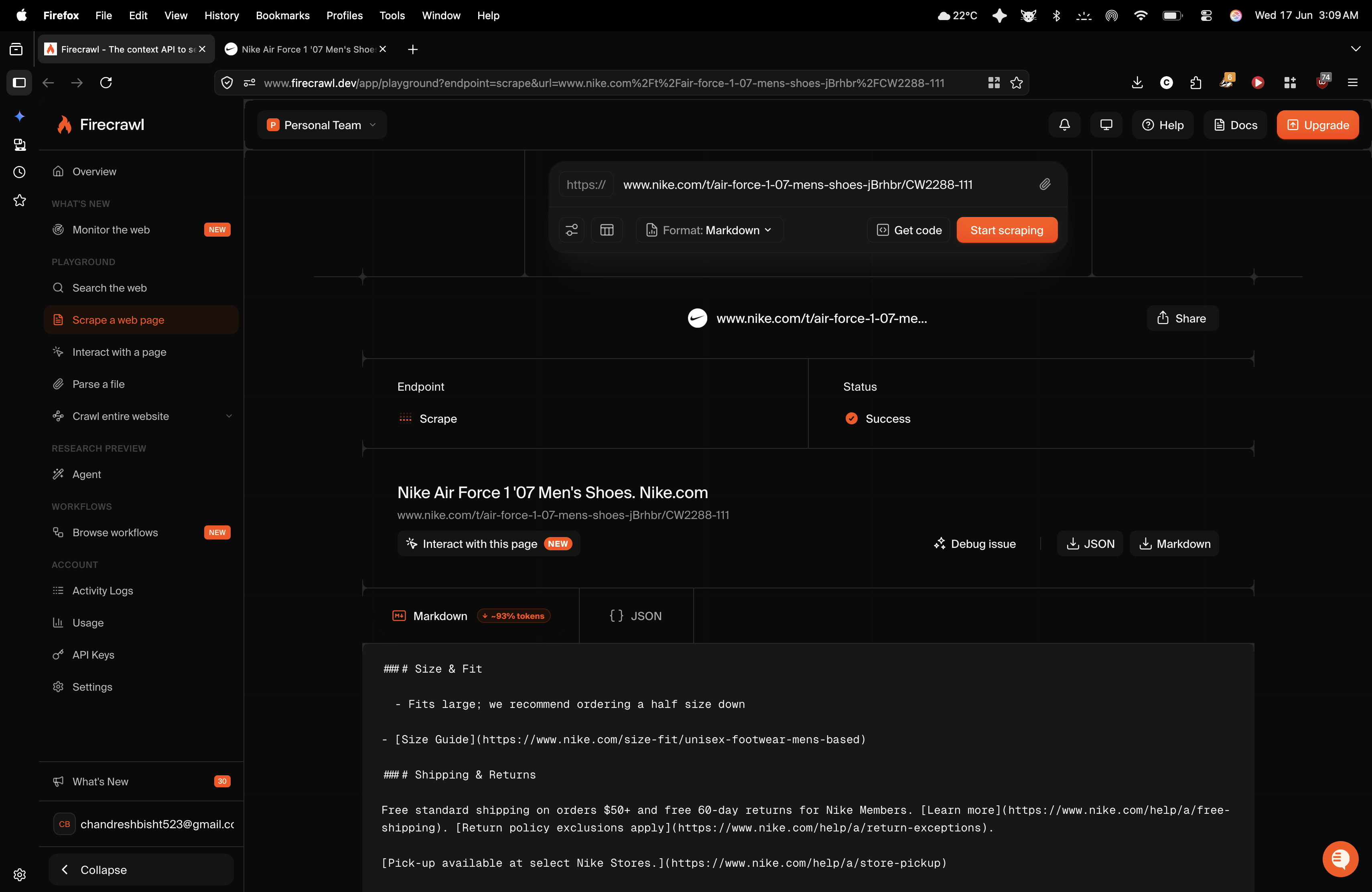
Firecrawl returned a successful Markdown scrape of the Nike product page with the rendered product title and key sections such as Size & Fit and Shipping & Returns. The researcher also observed that the full menu of dynamically loaded size variations was captured, confirming JavaScript execution. However, the output still contained extra localization links, asset references, and raw media-related clutter instead of a tightly cleaned product extract.
Anti-bot protected page accessIt got through the wall, but not cleanly.▾
Feature tested: Anti-bot protected page access
Result: Partial
Verdict: It got through the wall, but not cleanly.
Expected behavior: Accesses protected public pages with built-in proxy rotation and user-agent handling. On a Glassdoor job listing, Firecrawl bypassed the Cloudflare edge layer and returned live job content including title, employer, salary estimates, and technical skill requirements. The extracted text was still broken up by UI elements such as search controls, action buttons, internal links, and login fields.
Test case: Text prompt → Text prompt
Input type: Text prompt
Input used: Input artifact (Text prompt): Glassdoor job listing URL
Observed output: Output artifact (Text prompt): Observed result
Input artifact: Input artifact (Text prompt): Glassdoor job listing URL
Output artifact: Output artifact (Text prompt): Observed result
What changed: Text prompt transformed into Text prompt
Why it matters / Conclusion: Strong access layer for protected public pages, but the extracted Markdown still needs post-processing to become usable.
Accesses protected public pages with built-in proxy rotation and user-agent handling. On a Glassdoor job listing, Firecrawl bypassed the Cloudflare edge layer and returned live job content including title, employer, salary estimates, and technical skill requirements. The extracted text was still broken up by UI elements such as search controls, action buttons, internal links, and login fields.
Anti-bot page accessIt got through a protected jobs page and pulled useful job data, but the extracted text was still mixed with interface noise.▾
Feature tested: Anti-bot page access
Result: Passed
Verdict: It got through a protected jobs page and pulled useful job data, but the extracted text was still mixed with interface noise.
Expected behavior: Firecrawl can access and extract content from pages protected by anti-bot layers. This was tested on a Glassdoor software engineer jobs page, where it successfully returned live jobs-page content despite Cloudflare-style protections and heavy page chrome.
Test case: Text prompt → Image
Input type: Text prompt
Input used: Input artifact (Text prompt): Protected jobs page URL
Observed output: Output artifact (Image): Firecrawl returned a successful Markdown scrape of the Glassdoor jobs page, including jobs-page text and navigation links. The researcher reported that it bypas — firecrawl-firecrawl-glassdoor-scrape-markdown-output.png
Input artifact: Input artifact (Text prompt): Protected jobs page URL
Output artifact: Output artifact (Image): Firecrawl returned a successful Markdown scrape of the Glassdoor jobs page, including jobs-page text and navigation links. The researcher reported that it bypas — firecrawl-firecrawl-glassdoor-scrape-markdown-output.png
What changed: Text prompt transformed into Image
Why it matters / Conclusion: Very good at getting data out of protected pages, but the output is not clean enough to use as-is.
Firecrawl can access and extract content from pages protected by anti-bot layers. This was tested on a Glassdoor software engineer jobs page, where it successfully returned live jobs-page content despite Cloudflare-style protections and heavy page chrome.
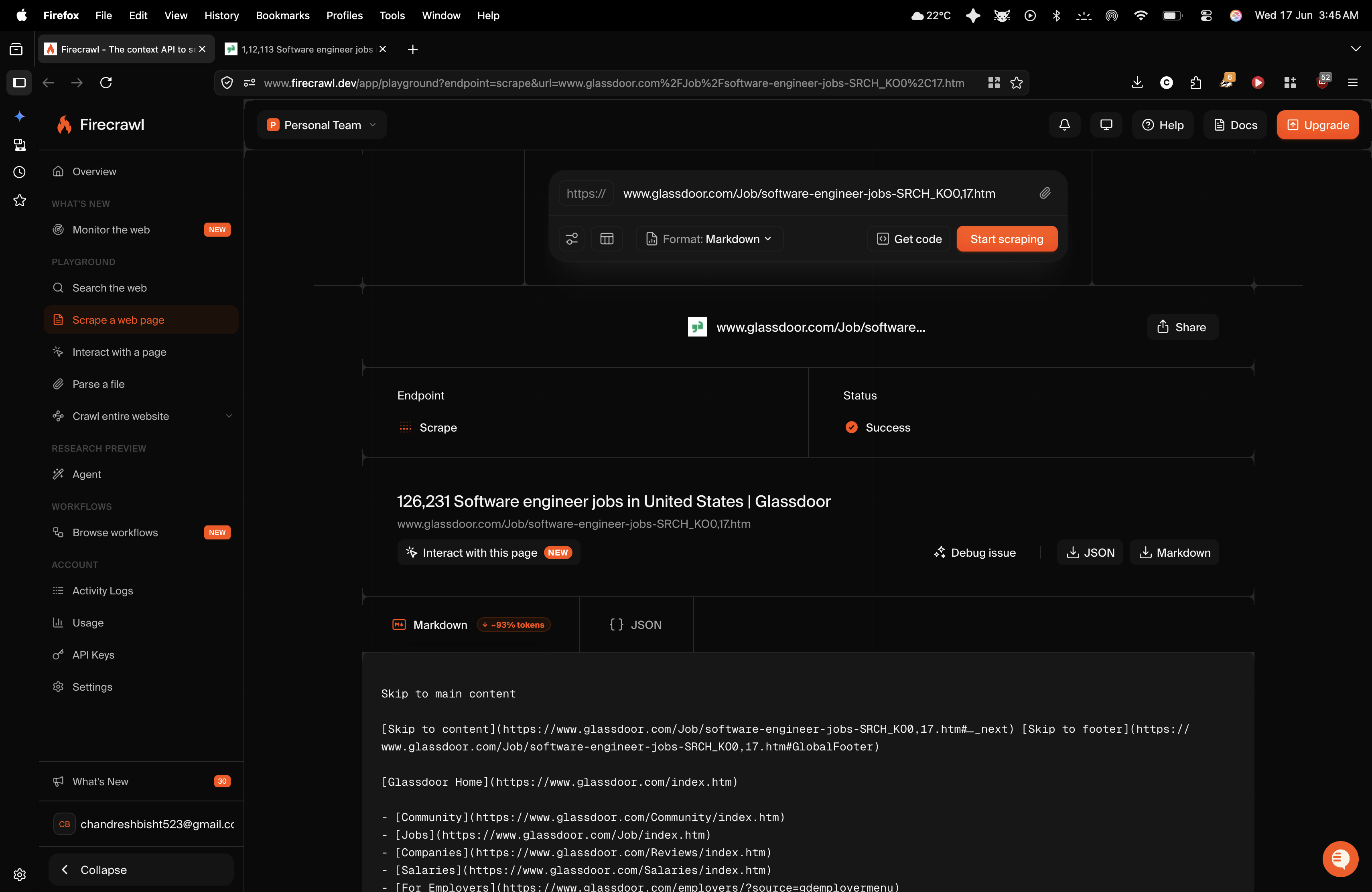
Firecrawl returned a successful Markdown scrape of the Glassdoor jobs page, including jobs-page text and navigation links. The researcher reported that it bypassed the page’s protection layer and pulled active job listings, company names, salary information, and technical skill details, but the resulting text was broken up by navigation controls, filters, internal links, and login-related layout elements.
Zero-selector Markdown extractionAccurate text capture, but poor semantic filtering.▾
Feature tested: Zero-selector Markdown extraction
Result: Partial
Verdict: Accurate text capture, but poor semantic filtering.
Expected behavior: Converts a public URL into Markdown without manual DOM selection. On a noisy recipe blog, Firecrawl preserved the article structure, ingredients, and step-by-step baking instructions with strong textual fidelity, but it also scraped the full primary navigation tree, sidebar/history components, thousands of user review nodes, and the footer into the same Markdown output.
Test case: Text prompt → Text prompt
Input type: Text prompt
Input used: Input artifact (Text prompt): Recipe blog URL
Observed output: Output artifact (Text prompt): Observed result
Input artifact: Input artifact (Text prompt): Recipe blog URL
Output artifact: Output artifact (Text prompt): Observed result
What changed: Text prompt transformed into Text prompt
Why it matters / Conclusion: Good at flattening page text into Markdown; not good at separating main content from site chrome.
Converts a public URL into Markdown without manual DOM selection. On a noisy recipe blog, Firecrawl preserved the article structure, ingredients, and step-by-step baking instructions with strong textual fidelity, but it also scraped the full primary navigation tree, sidebar/history components, thousands of user review nodes, and the footer into the same Markdown output.
Pricing
Subscription plans based on monthly API credits.
Pricing was reported directly in the research notes.
Is This Right For You?
A side-by-side guide based on our hands-on testing.
Banner Preview
How the embed badge will look on your site

Embed HTML
Copy this code to your website source
Quick Integration Guide
- 1Copy the HTML code block above.
- 2Paste it into your site's HTML or CMS editor.
- 3Banner appears instantly on your page.
- 4Links back to your tool profile here.
Similar Tools
Discover more AI tools like Firecrawl to enhance your workflow.